L'architecture en couches du réseau Internet
- Mia Combeau
- Internet | Réseau
- 22 août 2022
Table des matières
On connaît tous Internet. C’est le réseau informatique qui permet le transfert de données à l’échelle mondiale. Son ampleur est étourdissante avec environ 5 milliards d’utilisateurs, 200 millions de sites web actifs, 330 milliards d’emails envoyés par jour et 40 mille recherches sur Google chaque seconde. On y accède par divers moyens (Wi-Fi, fibre optique, le câble coaxial…), et à l’aide de divers appareils (ordinateurs, smartphones, montres connectées…).
Ce réseau, qui peut transférer un tel volume de données de façon si rapide et si fiable sur de telles distances via différents supports physiques, est un système extrêmement complexe. Comment peut-on donc espérer examiner et décrire cette gigantesque toile ? Il nous faut tout d’abord discerner quels sont les composantes physiques qui forment le réseau Internet. Ensuite, on pourra examiner l’architecture et les protocoles qui permettent l’envoi, le routage et la réception des données sous forme de paquets.
L’infrastructure d’Internet : un réseau de réseaux
En réalité, Internet est un réseau de réseaux. Il est composé de millions de réseaux publics et privés — commerciaux, universitaires, gouvernementaux.
Pour avoir accès à Internet en tant que particulier, on doit passer par un fournisseur de services Internet. Ce fournisseur est un réseau en lui-même : il connecte une multitude de domiciles et d’entreprises dans une zone géographique restreinte, au niveau local, régional ou même national. Les entreprises ont souvent leur propre réseau qu’elles connectent à Internet via leur fournisseur d’accès.
Pour raccorder leurs réseaux au niveau mondial, les fournisseurs d’accès doivent payer pour accéder aux services de fournisseurs de niveau supérieur. Ces fournisseurs là font le pont entre énormément de réseaux de niveau inférieur à l’échelle mondiale. Il n’y a qu’une dizaine de fournisseurs d’accès Internet de niveau 1, mais des centaines de milliers de fournisseurs de niveau inférieur. Les fournisseurs sont donc très variés dans l’étendue de la couverture de leur propre réseau. Certains franchissent des continents et des océans entiers, tandis que d’autres sont limités à des zones géographiques étroites. Les fournisseurs d’accès de niveau inférieur connectent aussi souvent leurs réseaux entre eux pour partager une connexion au fournisseur global de niveau 1.
Les grands fournisseurs de contenu comme Google ont aussi leurs propres réseaux. Ils se raccordent aux réseaux locaux de niveau inférieur autant que possible. Cela évite les frais plus importants des fournisseurs d’accès de plus haut niveau et augmente la vitesse de connexion pour leurs utilisateurs locaux.
https://www.codequoi.com//images/internet-architecture/internet*devices_routers_switches_hosts.drawio.png does not existLe matériel physique d’Internet
Tout système connecté au réseau Internet est un hôte. On peut diviser les hôtes en deux catégories : clients et serveurs. Un client, c’est souvent un ordinateur portable ou de bureau, un smartphone, une console de jeu vidéo. Ou encore, avec l’émergence de l’Internet des objets, un interphone bébé connecté, un moniteur de surveillance d’activité sismique ou d’habitat faunique, une montre connectée, etc. Un serveur, c’est une machine plus puissante qui stocke et distribue des pages de sites web, diffuse des vidéos en streaming, relaie des e-mails, etc.
Quand un hôte souhaite envoyer des données à un autre, il les découpe et y ajoute quelques octets en tête. Le résultat est une suite de paquets qui est expédiée à travers le réseau jusqu’à l’hôte de destination. Le destinataire doit ensuite rassembler les paquets et reconstituer les données après réception.
Les hôtes sont liés entre eux à l’aide de différents supports physiques sur lesquels peuvent circuler tous les bits d’un paquet. Ces supports peuvent être des lignes coaxiales, des câbles de cuivre, des fibres optiques ou encore des ondes radio. Mais les paquets vont rarement directement d’un hôte à l’autre. Ils doivent la plupart du temps passer par des commutateurs réseau (“switches” en anglais) et des routeurs. Ces deux appareils ont pour unique but de recevoir des paquets depuis leur ligne d’entrée et de les transférer via leur ligne de sortie la plus appropriée. Typiquement, un commutateur opère à l’intérieur d’un réseau tandis qu’un routeur fait l’interface entre deux réseaux ou sous-réseaux différents.
Chaque hôte, routeur ou commutateur est un nœud du réseau. Cette suite de relais par lequel passe un paquet pour arriver à sa destination, c’est ce qu’on appelle le routage.
La suite des protocoles Internet
La transmission de données sur Internet est gouvernée par un ensemble standardisé de protocoles de transfert de données. Ceux-ci permettent des applications et des services variés comme le courrier électronique, le World Wide Web, la messagerie instantanée, le partage de fichiers en pair-à-pair, le streaming, la téléconférence, etc.
On appelle la suite des protocoles Internet " TCP/IP", d’après ses deux protocoles fondamentaux : TCP (“Transmission Control Protocol”, ou, en français, le protocole de contrôle de transmissions) et IP (“Internet Protocol”, ou protocole internet). Mais ils sont loin d’être les seuls protocoles responsables de l’acheminement des paquets ! On regardera ces protocoles de plus près un peu plus loin.
Pour pouvoir soutenir autant de protocoles différents et acheminer les paquets sur autant de supports physiques différents vers autant de réseaux et d’hôtes différents, Internet doit avoir une architecture modulaire. C’est à dire que les protocoles de sa suite doivent pouvoir être plus ou moins interchangeables. C’est la principale raison pour laquelle ses protocoles s’organisent en couches distinctes.
Comprendre l’architecture en couches
Explorons l’idée de l’architecture en couches avec une analogie populaire : celle du système de transport aérien. C’est un système très complexe composé entre autres de billetteries, d’enregistrement de bagages, de compagnies aériennes, d’avions, de tours de contrôle du trafic aérien, et d’un système mondial de routage aérien…
Malgré tout, on peut assez facilement l’expliquer en termes des actions qu’on effectue afin de voyager en avion. On achète nos billets en billetterie, puis on enregistre nos bagages, et on embarque. L’avion décolle enfin et est routé vers sa destination. Puis, quand l’avion atterrit, on débarque, on récupère nos bagages et on va se plaindre en vain à l’agent de billetterie si le voyage nous a déplu. On peut même résumer le tout comme ceci :

Dans cet exemple, chaque couche implémente un service, une fonctionnalité, au départ comme à l’arrivée. Chaque couche offre son service en s’appuyant sur les services de la couche précédente et suivante. Toutes sont indispensables. Par contre, il est possible de changer les protocoles de chaque couche indépendamment. Par exemple, un aéroport pourrait très bien changer son protocole pour faire embarquer les passagers par âge plutôt que par place dans l’avion. L’aéroport ne devra pas pour autant changer quoique ce soit dans ses protocoles des couches bagages ou piste. On pourrait même remplacer tous les avions par des montgolfières sans affecter les quatre premières couches de protocoles aéroportuaires!
Les couches du modèle Internet
Bien sûr, dans l’analogie du transport aérien, le voyageur est le paquet de données. Pour pouvoir être expédiées et réceptionnées correctement, les données doivent traverser plusieurs couches de protocoles pour être transformées en paquets et extraites à l’arrivée :

Le modèle architectural d’Internet est donc organisé en pile de protocoles composée de 5 couches distinctes : la couche application, la couche transport, la couche réseau, la couche liaison des données et enfin la couche physique. Chaque hôte, commutateur, routeur et autres composants du réseau implémente au moins une partie de ces couches de protocoles. Tout comme chaque aéroport et tour de contrôle aérien implémente les couches de protocoles aériennes dans notre analogie précédente.
Examinons brièvement chaque couche du modèle architectural d’Internet pour comprendre quelles sont leurs fonctions.
La couche application
La couche application est composée des protocoles des applications réseau. Ces applications sont la raison d’être des réseaux informatiques. Comme il y a énormément d’applications Internet diverses et variées, la couche application englobe une grande diversité de protocoles différents. Et de nouveaux protocoles émergent tout le temps! Le tableau ci-dessous ne liste qu’une fraction des applications et des protocoles les plus communs :
| Application | Protocole(s) |
|---|---|
| Requête et transfert de pages Web | HTTP, HTTPS |
| Transfert de fichiers | FTP |
| Transfert et accès aux e-mails | SMTP, IMAP |
| Accès à distance via shell avec connexion sécurisée | SSH |
| Transfert de messages instantanés | IRC, XMPP |
| Synchronisation de l’horloge sur heure locale | NTP |
| Traduction des noms de domaine Internet en adresse IP | DNS |
| Streaming audio/vidéo | RMTP, HLS, SRT |
| Partage de fichiers en pair-à-pair | BitTorrent, eDonkey |
Un protocole de couche application est distribué entre hôtes : l’application de l’hôte expéditeur utilise le protocole pour échanger des paquets d’informations avec l’application équivalente de l’hôte destinataire. On appelle le paquet de données de la couche application un “message”.
La couche transport
La couche transport d’Internet a le rôle essentiel de fournir des services de communication aux applications des différents hôtes. Elle transporte les messages de la couche supérieure entre les points d’accès des applications.
Dans la suite des protocoles Internet, seuls deux protocoles dominent dans cette couche transport : TCP ou UDP. Les deux fonctionnent un peu différemment :
- TCP est un protocole de transport fiable, en mode connecté. C’est à dire qu’il s’assure d’avoir établi une connexion entre l’expéditeur et le destinataire avant l’envoi de données. Il s’assure aussi que le destinataire a bien reçu les données et les envoie de nouveau dans le cas contraire. Il garantit donc la livraison des messages de la couche application à sa destination. TCP contrôle aussi la vitesse du flux de données et peut ralentir sa vitesse de transmission lorsque le réseau est encombré et il découpe les longs flux de données en segments plus courts. Les applications les plus courantes qui utilisent TCP sont les transferts de fichiers, de messages et de pages Web ainsi que les services de streaming comme Youtube et Netflix.
- UDP fournit un service bien plus simple avec un mode de transmission sans connexion. Il ne régule pas le flux des données ni sa vitesse de transmission et ne garantit pas la livraison des messages. Cependant, la simplicité de ce protocole le rend utile pour la transmission rapide de petites quantités de données. Par exemple quand un serveur envoie vers de nombreux clients, ou bien quand la perte éventuelle d’un paquet est préférable à l’attente de sa retransmission. Le DNS, la voix sur IP ou les jeux en ligne sont des utilisations typiques d’UDP.
On appelle les paquets de la couche transport des “segments” .
La couche réseau
La couche réseau d’Internet est responsable de l’acheminement des paquets, appelés dans cette couche “datagrammes”, d’un hôte à l’autre. Tout comme on dépose une lettre accompagnée d’une adresse à la poste, le protocole de la couche transport de l’hôte expéditeur fournit un segment et l’adresse du destinataire à la couche réseau. La couche réseau a donc la t^ache de livrer ce segment à la couche transport de l’hôte destinataire.
L’IP, “protocole Internet” par définition, domine naturellement les protocoles de la couche réseau d’Internet. Ce protocole est sans pareille et tous les hôtes disposant d’une couche réseau et souhaitant être connecté à Internet doivent l’utiliser. C’est lui qui définit le datagramme de la couche réseau et les adresses IP qui identifient de façon unique tous les hôtes connectés. Il y a deux versions majeures d’IP: IPv4 et IPv6. Les deux assument la même fonction de manières un peu différentes.
Cependant, la couche réseau contient aussi d’autres protocoles de routage qui fonctionnent de concert avec IP. Ils ont typiquement pour fonction de déterminer le chemin qu’un datagramme doit prendre entre un expéditeur et un destinataire, comme RIP, OSPF, IS-IS et BGP. Un autre protocole, ICMP, a pour but d’envoyer des messages d’information ou d’erreur, par exemple lorsqu’un service ou un hôte est inaccessible.
Malgré le fait que la couche réseau d’Internet est composée d’autres protocoles en plus d’IP, on l’appelle souvent cette couche entière “IP”, ce qui souligne le fait qu’IP est véritablement le ciment qui lie l’Internet.
La couche liaison des données
La couche liaison des données doit déplacer un datagramme d’un nœud du réseau à l’autre (hôte, routeur, commutateur) jusqu’à destination. À chaque nœud, la couche réseau passe son datagramme à la couche liaison qui le déplace au nœud suivant de la route. Arrivé au nouveau nœud, la couche liaison livre le datagramme de nouveau à la couche réseau.
Les protocoles de la couche liaison sont, pour la plupart, liés au mode de transport physique entre chaque nœud du réseau. Les protocoles liaison sont Ethernet, Wi-Fi, DOCSIS, et PPP, entre autres. Certains protocoles assurent une livraison fiable des bits du paquet d’un nœud à l’autre, et d’autres non.
Comme les datagrammes doivent souvent passer par plusieurs supports physiques différents sur leur route entre expéditeur et destinataire, il est commun qu’il soit transporté par plusieurs protocoles de liaison différents. Par exemple, un datagramme peut au début être gérer par Ethernet sur le premier segment (entre le premier et le second nœud), puis PPP sur les trois prochains et enfin par Wi-Fi sur le dernier pour arriver au nœud de destination.
Les paquets de la couche liaison sont appelés “trames” (“frames” en anglais).
La couche physique
La couche physique, c’est la couche la plus basse du réseau Internet. Elle a pour but de déplacer chaque bit individuel des trames de la couche liaison d’un nœud au prochain. Naturellement, les protocoles de cette couche sont étroitement liées à la fois au support physique de déplacement des bits mais aussi aux protocoles de la couche liaison. Par exemple, Ethernet possède plusieurs protocoles de couche physique : un pour les paires de cuivre torsadés, un autre pour le câble coaxial, un autre pour la fibre optique, etc. Chacun de ces protocoles déplacent les bits sur le segment de manière différente.
Implémentation des couches dans différents dispositifs d’Internet
Étudions le diagramme ci-dessous pour suivre le trajet de données entre deux clients à travers les couches de protocoles au départ et à l’arrivée ainsi que lors de passages à travers un commutateur et un routeur.

La première constatation, c’est que seuls les hôtes implémentent toutes les couches de protocoles Internet. Le commutateur n’en implémente que deux et le routeur n’en implémente que trois. En effet, le commutateur ne s’inquiète que des deux dernières couches puisque son but est uniquement de transférer les bits de paquets au prochain nœud du réseau. Il doit implémenter les couches liaison et physique parce qu’il peut recevoir les paquets depuis un type de support matériel (un câble coaxial par exemple) et doit les transférer via un autre type de support (fibre optique, par exemple). Le routeur, lui, se soucie de l’acheminement des paquets vers la bonne adresse. Il doit donc implémenter en plus la couche réseau.
L’encapsulation des données
Comme on l’a vu, les paquets ont des noms différents selon la couche dont ils proviennent : message, segment, datagramme ou trame. C’est en raison du concept d’ encapsulation des données.
Dans le diagramme ci-dessus, on peut voir qu’à l’envoi, le message de la couche application (M) est transmise à la couche transport. Le protocole de la couche transport y ajoute une en-tête (“header” en anglais, d’où la notation Ht). Cette en-tête contient des informations qui permettent à la couche transport du destinataire de savoir à quelle application livrer le message et si les bits du paquet ont été corrompues en cours de route. Ensemble, on appelle le message et l’en-tête un segment. La couche transport encapsule donc le message de la couche application.
Ensuite, la couche réseau encapsule à son tour le segment de la couche transport en y ajoutant sa propre en-tête (Hn — n pour “network”), pour créer un datagramme. L’en-tête du datagramme contient entres autres les adresses de l’expéditeur et du destinataire. Enfin, le datagramme se voit encapsulé dans la couche liaison avec une en-tête (Hl) pour créer une trame.
Ainsi, à chaque couche, un paquet comprend deux champs : le champ d’en-tête (“header field”) et le champ de charge (“payload field”). La charge, c’est typiquement le paquet de la couche supérieure. À l’arrivée, chaque couche décapsule son paquet pour transmettre sa charge à la couche supérieure.
Évidemment, le processus d’encapsulation peut être bien plus compliqué que cela. Particulièrement dans le cas d’un flux de données important où la couche transport doit découper le message en plusieurs segments qui eux-mêmes pourront être découpés en plusieurs datagrammes dans la couche réseau. Dans ces cas-là, les segments devront être reconstitués à l’arrivée depuis leurs datagrammes et le message depuis ses multiples segments.
Le modèle OSI
Le modèle de l’architecture en couches d’Internet que nous avons examiné ci-dessus n’est pas le seul modèle réseau en existence. Dans les années 1970, lorsque les protocoles d’Internet n’étaient qu’à leurs débuts, plusieurs modèles de suites de protocoles étaient en développement. Parmi ceux-ci, un modèle en sept couches : le modèle OSI (“Open Systems Interconnection”). Malgré le fait qu’il ne soit jamais complètement adopté pour Internet, ce modèle est toujours utilisé dans les manuels et les formations. C’est à cause de son impact précoce sur l’enseignement des réseaux.
La seule véritable différence entre le modèle Internet et le modèle OSI, c’est le découpage de la couche application :
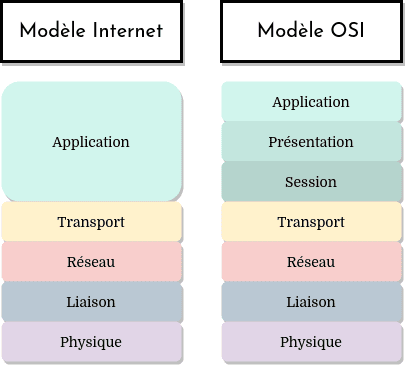
Les 5 couches communes aux deux modèles ont des fonctionnalités très similaires. Voyons donc les deux couches supplémentaires du modèle OSI, la couche de présentation et la couche de session.
La couche de présentation dans le modèle OSI aurait pour but de fournir des services d’interprétation des données échangées. Par exemple, elle offrirait des services de compression et de décompression, de cryptage et de décryptage ou encore de description des données pour que l’application n’ait pas à se soucier du format des données reçues.
La couche session permettrait de délimiter et de synchroniser l’échange des données. Par exemple, en offrant la capacité de construire un système de points de contrôle et de récupération des données.
Alors ces deux couches de services ne sont-elles pas importantes ? Et si une application avait besoin de ces fonctionnalités ? Dans le modèle Internet, c’est du ressort de l’application. Si le service est important, le développeur de l’application doit intégrer ces fonctionnalité dans l’application elle-même.
Sources et lectures supplémentaires
- Internet World Stats, World Internet Users and 2022 Population Stats [ InternetWorldStats - Archive]
- Internet Live Stats, Google Search Statistics [ InternetLiveStats]
- Kurose, J. F., Ross, K. W., 2013, Computer Networking: A Top Down Approach, Sixth Edition, Chapter 1: Computer Networks and the Internet, pp. 1-82.
- Site du Zéro, Tutoriel : Apprenez le fonctionnement des réseaux TCP/IP [ sdz.com]
- Zuckerman E., McLaughlin A., Introduction to Internet Architecture and Institutions [ harvard.edu]
- Wikipédia, Internet [ Wikipédia]
- Wikipédia, Suite des protocoles Internet [ Wikipédia]