Créer et tuer des processus fils en C
- Mia Combeau
- C | Informatique
- 22 octobre 2022
Table des matières
Que ce soit pour exécuter un autre programme depuis le notre ou pour exécuter une partie de notre programme en parallèle, il est souvent très utile de créer des processus fils. On peut ensuite patiemment attendre qu’ils finissent leur tâches, ou même, si l’on se sent particulièrement meurtrier, les tuer prématurément !
Alors qu’est-ce exactement qu’un processus ? Comment peut-on en créer, pourquoi les attendre ou les tuer ? C’est ce que nous allons voir ici.
Qu’est-ce qu’un processus ?
Les programmes que nous écrivons sont des ensembles d’instructions et d’opérations destinées à être exécutées par un ordinateur. Un programme et tous ses fichiers sont sauvegardés sur disque dur et ne font rien en soi.
Quand on exécute un programme, que ce soit avec une commande shell, en double-cliquant sur son icône ou automatiquement au démarrage de la machine, le système charge ses instructions en mémoire vive et les exécute les unes après les autres. C’est un programme dans cet état, en cours d’exécution, qu’on appelle un processus.
Un programme existe sur disque dur ; un processus en mémoire vive.
Le système d’exploitation gère tous les processus et alloue à chacun d’entre eux sa propre zone de mémoire vive : sa propre stack, sa propre heap, son propre pointeur d’instruction, etc. Cela implique qu’un processus ne peut pas facilement accéder à la mémoire ou aux instructions d’un autre processus. Chaque processus est donc une entité distincte.
La hiérarchie des processus
Pour voir tous les processus actifs sur le système Unix, on peut lancer la commande :
$ ps -e
On peut voir ici que chaque processus se voit assigné un PID ( P rocess ID entifier, ou “identifiant de processus”). C’est un entier positif par lequel on peut reconnaître un processus de façon unique. On peut d’ailleurs voir le PID de n’importe quel processus avec la commande pidof :
$ pidof systemd
$ pidof top
$ pidof pidof
Mais ce n’est pas le seul PID que possèdent les processus. Ils ont aussi une référence à leur processus père : le PPID ( Parent Process IDentifier, ou “identifiant de processus père”). Par exemple, on peut voir le PID et le PPID du shell de notre terminal avec la commande suivante :
$ echo "PID = $$; PPID = $PPID"
En effet, les processus sont organisés de manière hiérarchique avec :
- des processus père (ou parent en anglais), qui engendrent des processus fils,
- des processus fils (ou child en anglais) crées par leur processus père et qui peuvent à leur tour engendrer d’autres fils.
Par exemple, quand on indique au shell de lancer une commande telle que ls, le shell crée un processus fils qui a pour tâche d’exécuter le programme ls. Si le shell exécutait directement le programme ls sans créer de fils au préalable, le processus du shell serait entièrement remplacé par le programme ls et on ne pourrait plus rien faire dans notre shell…
Au démarrage d’un système de type Unix, il n’y a qu’un seul processus, appelé init, qui possède le PID 1. Celui-ci est l’ascendant direct ou indirect de tous les autres processus lancés sur le système.
Fork : donner naissance à un processus fils
L’appel système fork va permettre à notre processus de donner naissance à un nouveau processus qui sera sa copie conforme et qui sera exécuté en parallèle. Notre processus sera donc le père du nouveau processus fils. Le nom même de la fonction, fork (“fourche” en français), fait référence à la fourche d’un arbre généalogique.
Voyons-voir le prototype de fork de la bibliothèque <unistd.h> :
pid_t fork(void);
C’est assez simple comme prototype ! L’important, c’est de connaitre la valeur de retour de cette fonction : elle nous informera si la création du processus fils s’est bien passée, mais pas seulement…
Distinguer le processus père du processus fils
Comme le fils est un clone du père, il va avoir exactement le même code que le processus père. Pourtant, on va sans doute vouloir donner au fils des instructions différentes de celles du père. Cette valeur de retour de fork, un nombre de type pid_t, ne retourne pas le même PID au père et au fils, ce qui nous permet de les différencier. Voici les valeurs de retour possibles de la fonction fork :
- le père reçoit en retour le PID du fils,
- le fils reçoit 0,
- et en cas d’erreur,
forkrenvoie -1.
En d’autres termes, si on voit 0 comme retour du fork, on sait qu’on est dans le processus fils, si on voit un PID (un nombre supérieur à 0), on sait qu’on est dans le père.
Il faut aussi savoir que le processus fils hérite du pointeur d’instruction (" program counter" ou " instruction pointer" ) du père. Le pointeur d’instruction, ou le compteur ordinal, c’est un registre qui contient l’adresse mémoire de l’instruction en cours d’exécution. Il est automatiquement incrémenté pour pointer sur l’instruction suivante. Cela veut dire que quand on fork le fils, il en sera au même endroit dans le code que le père : le fils ne recommence pas toutes les instructions depuis le début !
Donc notre code pour créer un processus fils ressemblera sans doute beaucoup à ceci :
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
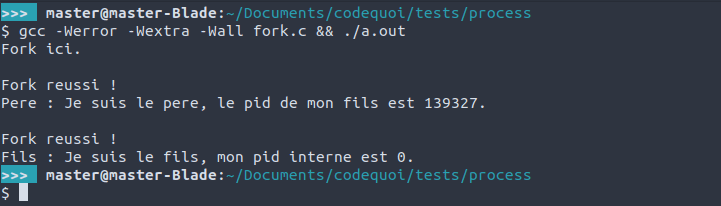
printf("Fork ici.\n");
pid = fork();
if (pid == -1)
{
// Si fork renvoie -1, il y a eu une erreur !
return (1);
}
printf("\nFork reussi !\n");
if (pid == 0)
{
// La valeur de retour de fork
// est 0, ce qui veut dire qu'on est
// dans le processus fils
printf("Fils : Je suis le fils, mon pid interne est %d.\n", pid);
}
else if (pid > 0)
{
// La valeur de retour de fork
// est différente de 0, ce qui veut dire
// qu'on est dans le processus père
printf("Pere : Je suis le pere, le pid de mon fils est %d.\n", pid);
}
return(0);
}
Mémoire dupliquée mais pas partagée
On l’a vu, le processus fils est une copie conforme de son processus père. Au moment de la création du fils, les deux processus sont absolument identiques. Ils ont le même code, les mêmes descripteurs de fichiers ouverts, les mêmes données en mémoire, etc. Mais cette mémoire, bien qu’identique, n’est pas partagée entre les deux processus. Cela veut dire que si le processus père change la valeur d’une variable après avoir créé son processus fils, le fils ne verra pas le changement s’il consulte cette même variable.
Tentons d’illustrer ce point avec un exemple :
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
// Routine du processus fils :
void routine_fils(pid_t pid, int *nb)
{
printf("Fils : Coucou! Je suis le fils. PID recu de fork = %d\n", pid);
printf("Fils : Le nombre est %d\n", *nb);
}
// Routine du processus père :
void routine_pere(pid_t pid, int *nb)
{
printf("Pere : Je suis le pere. PID recu de fork = %d\n", pid);
printf("Pere : Le nombre est %d\n", *nb);
*nb *= 2;
printf("Pere : Le nombre modifie est %d\n", *nb);
}
int main(void)
{
pid_t pid; // Stocke le retour de fork
int nb; // Stocke un entier
nb = 42;
printf("Avant fork, le nombre est %d\n", nb);
pid = fork(); // Création du processus fils
if (pid == -1)
return (EXIT_FAILURE);
else if (pid == 0) // Retour de fork est 0, on est dans le fils
routine_fils(pid, &nb);
else if (pid > 0) // Retour de fork > 0, on est dans le père
routine_pere(pid, &nb);
return (EXIT_SUCCESS);
}
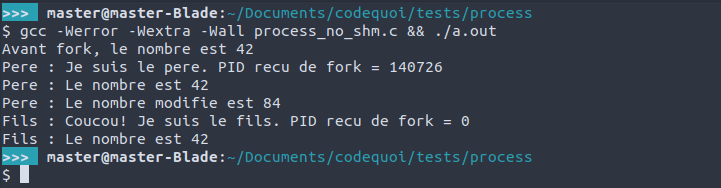
Ici, après la création du processus fils avec fork, le processus père double la valeur du nombre qu’on lui fournit, mais le fils imprime la valeur originale de ce nombre, vu qu’il n’est pas au courant de la modification apportée par le père.
Nous étudierons dans de prochains articles quelques méthodes pour établir une communication inter-processus, en particulier avec les pipes, les sémaphores et les signaux. Mais les processus fils peuvent aussi communiquer de façon unilatérale avec leur processus père pour lui indiquer leur statut de fin une fois leurs tâches accomplies. Mais pour pouvoir récupérer ce statut de fin, il faut avant tout penser à ce que le père attende ses fils.
Wait : attendre les processus fils
Un processus père ne s’occupe pas systématiquement de ses fils. L’exemple suivant force le processus fils à attendre 1 seconde avant de terminer, mais laisse le processus père finir immédiatement :
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
pid = fork();
if (pid == -1)
return (1);
if (pid == 0)
{
printf("Fils : Je suis le fils, mon pid interne est %d.\n", pid);
sleep(1); // Attendre 1 seconde.
printf("Fils : Termine !\n");
}
else if (pid > 0)
{
printf("Pere : Je suis le pere, le pid de mon fils est %d.\n", pid);
printf("Pere : Termine !\n");
}
return (0);
}
Le résultat est pour le peu étrange :
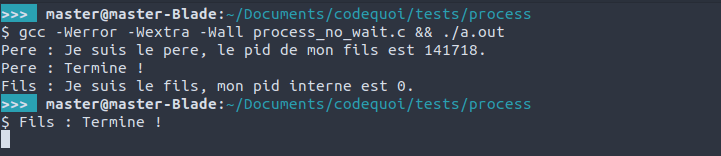
On nous rend l’invite de commandes avant même que le processus fils ait terminé. C’est parce que le shell attend uniquement que notre processus père (son fils) se termine. Il ne se soucie pas du processus fils de notre programme (le petit-fils du shell). Dans un cas comme celui-ci, quand le père se termine sans attendre son fils, le fils devient un processus orphelin. Il est alors adopté par init (son PPID devient 1) et promptement éliminé du système.
Attendre pour éviter les zombies
De plus, on veut aussi éviter le mauvais sort des zombies ! Un processus zombie, c’est un processus qui a terminé sa tâche mais qui reste présent en attendant que son père le prenne en compte. Le système lui aura déjà désalloué ses ressources (code, données, pile d’exécution) mais conserve son bloc de contrôle, dont son PID. On peut observer un zombie en action si l’on met le processus père dans une boucle infinie :
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
pid = fork();
if (pid == -1)
return (1);
if (pid == 0)
{
printf("Fils : Je suis le fils, mon pid interne est %d.\n", pid);
printf("Fils : Termine !\n");
}
else if (pid > 0)
{
printf("Pere : Je suis le pere, le pid de mon fils est %d.\n", pid);
while (1) // Boucle infinie, le père ne termine jamais !
usleep(1);
}
return (0);
}
Maintenant, on peut lancer notre programme :

Mais avant de tuer le processus infini avec ctrl-c, on peut ouvrir un nouveau terminal et lancer la commande ps aux | grep <pid_du_fils> | grep Z+ pour voir notre zombie :

En soi, un processus zombie ne pose pas de problème tant que le processus père réceptionne bien son état. Il ne consomme pas d’énergie et ne prend pas de place dans l’espace mémoire. Les processus zombies sont aussi automatiquement éliminés par leur père adoptif init s’ils deviennent orphelins. Cependant, si le père est un processus qui ne s’arrête jamais (serveur, tâche de fond, etc.) et qu’il engendre des fils à intervalles réguliers sans jamais attendre leurs retours, la table des processus du système risque de se saturer. Cela bloquerait le système, qui ne pourra plus créer de nouveaux processus.
Notre processus père va donc devoir mieux s’occuper de ses fils ! Il peut faire cela avec les appels système wait et waitpid.
Les appels système wait et waitpid
Pour suspendre l’exécution du processus père jusqu’à ce que l’état de son fils change, on peut utiliser l’appel système wait ou waitpid de la bibliothèque <sys/wait.h>, dont les prototypes sont :
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
La différence entre les deux se ressent surtout lorsqu’un processus a plusieurs processus fils. L’appel wait va récupérer le premier fils qui a terminé, tandis que waitpid pourra attendre le fils avec le PID qu’on lui fournit en particulier et ignorer tous les autres. De plus, waitpid nous fournit la possibilité d’indiquer certaines options.
Le paramètre commun aux deux appels système est :
- status : un pointeur vers une variable de type
int, dans lequelwaitetwaitpidpeuvent stoker le statut de fin du processus fils qu’on récupère. On pourra ensuite analyser ce nombre pour déterminer si le fils a correctement terminé son exécution ou s’il a été interrompu par exemple.
Les deux autres paramètres de waitpid sont :
- pid : le PID du processus fils qu’on doit attendre. Le processus père connait ce PID grâce au retour de la fonction
forklors de la création du fils. On peut aussi spécifier -1 ici pour attendre n’importe quel fils qui termine en premier, comme le faitwait. (Et en effet,waitpid(-1, status, 0)est exactement équivalent àwait(status).) - options : il existe quelques options possibles pour
waitpid. Parmi elles, l’option parfois bien utileWNOHANG, qui forcewaitpidà retourner immédiatement si le fils n’a pas fini son exécution. Sans cette option, le processus père restera par défaut bloqué tant que le fils n’a pas terminé.
En cas de réussite, wait et waitpid renvoient tous deux le PID du fils qui s’est terminé, sinon ils renvoient -1. Dans le cas de waitpid, il peut renvoyer 0 si l’option WNOHANG lui est spécifiée et que le fils qu’il attend n’a pas encore changé d’état.
Analyser le statut de fin d’un processus fils
Les fonctions wait et waitpid nous fournissent tous deux un statut qui nous permet d’avoir pas mal d’informations concernant la façon dont le fils a terminé son exécution. Le statut est un entier qui contiendra non seulement le statut de fin mais aussi d’autres détails qui indiquent pourquoi le fils s’est terminé. On peut alors savoir si le fils a véritablement terminé toutes ses tâches, ou s’il a été interrompu, et récupérer son code de sortie.
On peut inspecter le statut à l’aide de plusieurs macros :
WIFEXITED(status): renvoie vrai si le fils s’est terminé normalement, par exemple en faisant appel à exit ou en terminant via la fonction principale, main.WEXITSTATUS(status): a utiliser uniquement siWIFEXITEDa renvoyé vrai. Renvoie le code de sortie du fils, c’est à dire le nombre que le fils a spécifié lors de son appel à exit ou lors de son retour dans le main.
WIFSIGNALED(status): renvoie vrai si le fils a été terminé de force par un signal.WTERMSIG(status): a utiliser uniquement siWIFSIGNALEDa renvoyé vrai. Renvoie le numéro du signal qui a provoqué la terminaison du fils.
Exemple de wait/waitpid et d’analyse du statut de fin du processus fils
Créons un petit programme qui engendrera un fils. Ce fils terminera avec le statut de fin qu’on pourra définir au moment de la compilation. Le processus père attendra son fils avec waitpid (mais wait est tout à fait possible aussi), puis analysera le statut qu’il reçoit.
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <stdio.h>
// Définition d'une macro pour un statut de fin
// particulier pour le fils (si on ne l'indique pas à la compilation
// avec -D CHILD_EXIT_CODE=[nombre], par défaut elle sera à 42 :
#ifndef CHILD_EXIT_CODE
# define CHILD_EXIT_CODE 42
#endif
// Définition d'une macro pour le statut de fin
// du fils auquel on s'attend
#define EXPECTED_CODE 42
// Routine du processus fils :
void routine_fils(pid_t pid)
{
printf("\e[36mFils : Coucou! Je suis le fils. PID recu de fork = %d\e[0m\n",
pid);
printf("\e[36mFils : Je sors avec le statut de fin %d.\e[0m\n",
CHILD_EXIT_CODE);
exit(CHILD_EXIT_CODE);
}
// Routine du processus pere :
void routine_pere(pid_t pid)
{
int status;
printf("Pere : Je suis le pere. PID recu de fork = %d\n", pid);
printf("Pere : J'attends mon fils qui a le PID [%d].\n", pid);
waitpid(pid, &status, 0); // Attendre le fils
// ou wait(&status);
printf("Pere : Mon fils est sorti avec le statut %d\n", status);
if (WIFEXITED(status)) // Si le fils est sorti normalement
{
printf("Pere : Le statut de fin de mon fils est %d\n",
WEXITSTATUS(status));
if (WEXITSTATUS(status) == EXPECTED_CODE)
printf("Pere : C'est le statut que j'attendais !\n");
else
printf("Pere : Je ne m'attendais pas a ce statut-la...\n");
}
}
int main(void)
{
pid_t pid; // Stocke le retour de fork
pid = fork(); // Création d'un processus fils
if (pid == -1)
return (EXIT_FAILURE);
else if (pid == 0) // Processus fils
routine_fils(pid);
else if (pid > 0) // Processus père
routine_pere(pid);
return (EXIT_SUCCESS);
}
On peut compiler ce code avec le drapeau -D pour définir le statut de fin que le processus fils devra utiliser, comme ceci :
$ gcc wait.c -D CHILD_EXIT_CODE=42 && ./a.out
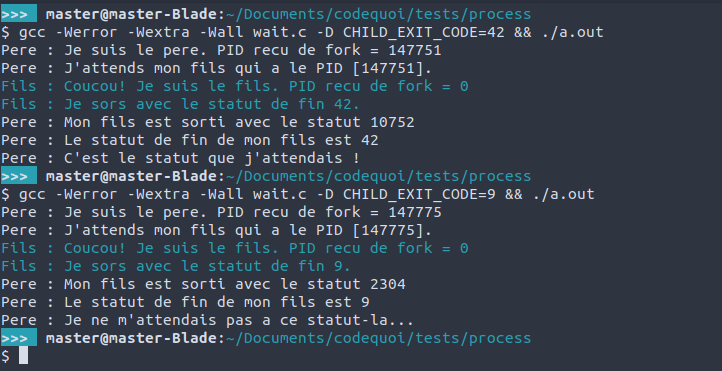
Le résultat pour un statut de sortie 42 et ensuite 9 :
Kill : tuer les processus fils
C’est quelque peu sinistre, mais on peut, au besoin, tuer notre processus fils. Pour cela, il suffit d’utiliser la fonction kill de la bibliothèque <signal.h> afin d’envoyer un signal au processus fils de tout arrêter immédiatement. Le prototype de la fonction est le suivant :
int kill(pid_t pid, int sig);
Les paramètres qu’on doit fournir sont :
- pid : l’identifiant du processus qu’on veut tuer.
- sig : le signal à envoyer au processus pour le tuer. Il y a plusieurs signaux possibles qu’on peut envoyer avec
kill, chacun avec ses nuances (voir man 7 signal), mais les plus courants sont sans douteSIGTERM(signal de fin) ouSIGKILL(arrêt forcé immédiat).
La fonction kill renvoie 0 en cas de succès et en cas d’erreur, -1, avec un errno pour indiquer les détails de l’erreur. Pour plus de détails, lire l’article sur l’envoi, l’interception et le blockage de signaux.
Exemple d’usage de kill
Dans l’exemple suivant, nous allons créer trois fils qui vont tourner à l’infini, les tuer avec un signal et analyser leur retours :
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <signal.h>
#include <stdio.h>
// Routine du processus fils :
void routine_fils(void)
{
printf("\e[36mFils : Coucou! Je suis un fils. Je tourne a l'infini.\e[0m\n");
while (1) // Tourne a l'infini
continue;
}
// Routine du processus pere :
void kill_and_get_children(pid_t *pid)
{
int status;
int i;
printf("Pere : Je suis le pere filicide.\n");
i = 0;
while (i < 3) // Tue les 3 fils avec un signal
{
kill(pid[i], SIGKILL);
i++;
}
printf("Pere : J'ai tue tous mes fils mwahahaaa !\n");
i = 0;
while (i < 3) // Récupère la sortie de chaque fils
{
waitpid(pid[i], &status, 0);
if (WIFEXITED(status))
printf("Fils [%d] a terminé normalement.\n", pid[i]);
else if (WIFSIGNALED(status))
{
printf("Fils [%d] a ete interrompu.\n", pid[i]);
if (WTERMSIG(status) == SIGTERM)
printf("\e[31mFils [%d] a recu le signal %d, SIGTERM\e[0m\n",
pid[i], WTERMSIG(status));
if (WTERMSIG(status) == SIGKILL)
printf("\e[31mFils [%d] a recu le signal %d, SIGKILL\e[0m\n",
pid[i], WTERMSIG(status));
}
i++;
}
}
int main(void)
{
pid_t pid[3]; // Stocke les retours de fork
int i;
i = 0;
while (i < 3) // Crée 3 fils
{
pid[i] = fork(); // Création d'un processus fils
if (pid[i] == -1)
return (EXIT_FAILURE);
else if (pid[i] == 0)
routine_fils();
else if (pid[i] > 0)
printf("Fils #%d cree avec pid = %d\n", i, pid[i]);
usleep(1000); // Décaler les fils un peu dans le temps
i++;
}
kill_and_get_children(pid);
return (EXIT_SUCCESS);
}
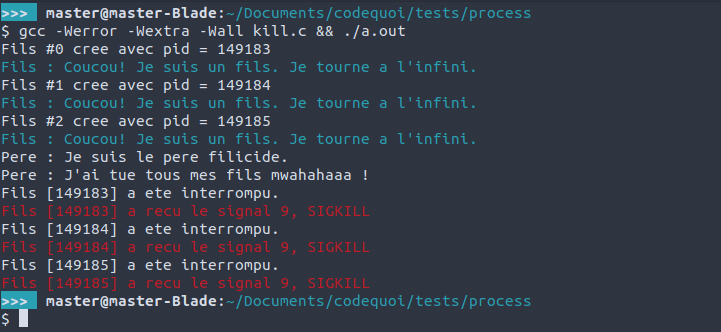
Ici, on voit bien que dès que le signal de fin leur parvient, les processus fils s’arrêtent immédiatement. Le processus père qui les attend reçoit leur statut et peut voir exactement quel signal a été utilisé pour forcer leur terminaison. En changeant simplement le signal qu’on envoie avec kill, on aura un résultat un peu différent.
Astuces pour déboguer un programme avec des processus fils
Tout bon programme ne doit avoir aucune fuite de mémoire. Dans le cas d’un programme qui crée des processus fils, aucun de ces fils ne doivent avoir de fuites de mémoire non plus. On doit donc s’assurer de libérer toute mémoire allouée à la terminaison de chaque processus. Si l’on tue nos processus fils avec un signal, on doit veiller à quel signal utiliser : SIGTERM, SIGINT et SIGKILL n’ont pas tous les mêmes implications en termes de fuites de mémoire !
Déboguer un programme qui crée des processus fils peut s’avérer assez accablant. En effet, Valgrind affiche souvent un torrent de messages d’erreurs, provenant non seulement du processus père mais aussi de chacun des fils ! Heureusement, Valgrind nous offre une option nous pour faire taire les erreurs dans les fils : --child-silent-after-fork=yes. Une fois qu’on a résolu les erreurs du processus père, on peut enlever cette option pour examiner les erreurs propres aux fils.
Une autre astuce à partager, une petite question à poser, ou une découverte bizarroïde à propos des processus fils ? Je serai ravie de lire et de répondre à tout ça dans les commentaires. Bon code !
Sources et lectures supplémentaires
-
Manuel du programmeur Linux :
-
Wikipédia, init [wikipedia.org]
-
Geeks for Geeks, fork() in C [geeksforgeeks.org]
-
Aline, Les processus zombies [it-connect.fr]
-
Tecmint, All You Need To Know About Processes in Linux [tecmint.com]