Creating and Killing Child Processes in C
- Mia Combeau
- C | Computer science
- October 22, 2022
Table of Contents
In order to execute another program within ours or to execute part of our program simultaneously, it can often be very useful to create child processes. Then, all we need to do is patiently wait for them to finish their tasks, or, if we’re feeling particularly murderous, kill them prematurely!
So what exactly is a process? How can we create child processes, and why wait for them or kill them? That is what we’ll explore in this article.
What is a Process?
The programs we write are sets of instructions and operations meant to be executed by a computer. A program and all of its files are saved on a hard drive and do nothing, per se.
When we execute a program, whether it be with a shell command, by double-clicking an icon or automatically at startup, the system loads its instructions into RAM and executes them one after the other. A program in this state of execution is what we call a process.
A program exists on a hard drive; a process exists in RAM.
The operating system manages all processes and allocates a memory zone to each of them. Each has its own stack, its own heap, its own instruction pointer, etc. This means that a process cannot easily access another process’ memory or instructions. Each process is therefore a distinct entity.
A Hierarchy of Processes
To see all the active processes on a Unix system, we can use the following command :
$ ps -e
We can see here that each process is assigned a PID ( P rocess ID entifier), a non-negative integer by which we can uniquely identify a process. We can also check any process’ PID with the pidof command:
$ pidof systemd
$ pidof top
$ pidof pidof
But that isn’t the only PID a process has. It also receives a reference to its parent process: a PPID ( P arent P rocess ID entifier). For example, we can check both the PID and PPID of the shell program in our terminal with the following command:
$ echo "PID = $$; PPID = $PPID"
So processes are organized in a hierarchy, with:
- parent processes that create child processes,
- child processes that are created by their parent process and can in turn create child processes of their own.
For example, when we input a command into the shell like ls, the shell creates a child process whose job it is to execute the ls program. If the shell executed the ls program directly without first creating a child, the shell process would be overwritten by the ls program and we wouldn’t be able to continue using our shell…
At startup, a Unix system only has one process, called init, which has PID 1. That process is the direct or indirect ancestor of every other process executed on the system.
Fork: Creating a Child Process
The fork system call will allow our process to create a new process, which will be its exact clone and executed simultaneously. In this way, our initial process will be the parent and the new process, its child. In fact, the very name of the system call, fork, is like the fork of a family tree.
Let’s take a look at the prototype of fork, from the <unistd.h> library:
pid_t fork(void);
Simple enough, for a prototype! The important thing to understand is this function’s return value. It will let us know if the child process was successfully created, but that’s not all…
Distinguishing Between the Parent and Child Processes
Since the child is a clone of the parent, it will have the same exact code. However, we probably want to give the child process different instructions than its parent. The fork system call’s return value, an integer of type pid_t, does not return the same PID to the parent and to the child. So this is what we will use in order to differentiate them. Here are the fork function’s possible return values:
- the parent receives the child’s PID,
- the child receives 0,
- and in the event of an error,
forkreturns -1.
In other words, if we see 0 as the return value of fork, we know we are in the child process. Otherwise if we see a PID, we know we are in the parent.
We should also note that the child process inherits the parent’s instruction pointer (or program counter). This instruction pointer is a processor register that contains the memory address of the current instruction and is automatically incremented to point on the next instruction to execute. This means that when we fork a child process, it will be at the same place in the code that the parent is: the child doesn’t start all the way from the beginning!
So our code to create a child process will probably look a lot like this:
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
printf("Fork here.\n");
pid = fork();
if (pid == -1)
{
// If fork returns -1, there was an error!
return (1);
}
printf("\nFork successful!\n");
if (pid == 0)
{
// Fork's return value is 0:
// we are now in the child process
printf("Child: I'm the child, my internal pid is %d.\n", pid);
}
else if (pid > 0)
{
// Fork's return value is not 0
// which means we are in the parent process
printf("Parent: I'm the parent, my child's pid is %d.\n", pid);
}
return(0);
}
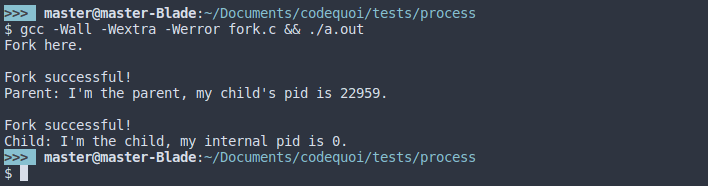
Memory Duplicated but Not Shared
As we’ve seen, a child process is an exact copy of its parent process. When a child is created, it is identical to its parent in every way. It has the same code, the same open file descriptors, the same data stored in memory, etc. But the fact that this memory is identical does not mean it is shared between the two processes. If the parent process changes the value of one of its variables after creating the child, the child process will not see any change when it reads the same variable.
Let’s attempt to illustrate this point with an example:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
// Child process routine:
void child_routine(pid_t pid, int *nb)
{
printf("Child: Hi! I'm the child. PID received from fork = %d\n", pid);
printf("Child: The number is %d\n", *nb);
}
// Parent process routine:
void parent_routine(pid_t pid, int *nb)
{
printf("Parent: I'm the parent. PID received from fork = %d\n", pid);
printf("Parent: The number is %d\n", *nb);
*nb *= 2;
printf("Parent: The modified number is %d\n", *nb);
}
int main(void)
{
pid_t pid; // Stores the return value of fork
int nb; // Stores an integer
nb = 42;
printf("Before fork, the number is %d\n", nb);
pid = fork(); // Creating the child process
if (pid == -1)
return (EXIT_FAILURE);
else if (pid == 0) // The pid is 0, this is the child process
child_routine(pid, &nb);
else if (pid > 0) // The pid is > 0, this is the parent
parent_routine(pid, &nb);
return (EXIT_SUCCESS);
}
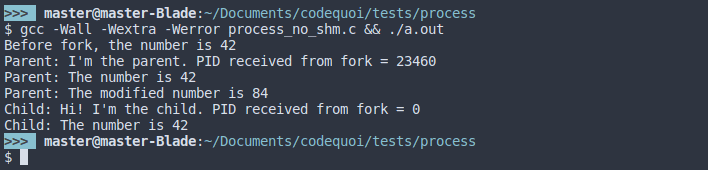
Here, after the child process’ creation, the parent doubles the value of the given number using a memory address pointer. But the child prints the number’s original value, unaware of the parent’s modification.
In future articles, we will study a couple of methods to establish inter-process communication, notably with pipes, semaphores and signals. But child processes can also communicate unilaterally with its parent process to indicate its exit status once its tasks have been completed. However, in order to retrieve this exit status, the parent must not forget to wait for its children.
Wait: Stick Around for the Child Processes
The parent process does not systematically take care of its children. In the following example, we will force the child process to sleep for 1 second before ending, but let the parent terminate right away:
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
pid = fork();
if (pid == -1)
return (1);
if (pid == 0)
{
printf("Child: I'm the child, my internal pid is %d.\n", pid);
sleep(1); // Sleep 1 second.
printf("Child: Done!\n");
}
else if (pid > 0)
{
printf("Parent: I'm the parent, my child's pid is %d.\n", pid);
printf("Parent: Done!\n");
}
return (0);
}
The result is a little strange:

Our command prompt returns before the child process is even terminated. This is because our shell is only waiting for our parent process (its child) to finish. It doesn’t know or care about our program’s child process (its grand-child). In a case like this, when the parent finished without waiting for its child, the child becomes an orphan process. It is then adopted by init (its PPID becomes 1) and is quickly eliminated from the system.
Waiting to Avoid Zombies
Plus, we really want to avoid a zombie outbreak. A zombie process is a process that has finished its task but stays on the system, waiting for its parent to acknowledge it. The system will already have freed its resources (code, data, execution stack) but saved its process control block, including its PID. We can observe a zombie in action if we create an infinite loop in our parent process:
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
pid = fork();
if (pid == -1)
return (1);
if (pid == 0)
{
printf("Child: I'm the child, my internal pid is %d.\n", pid);
printf("Child: Done!\n");
}
else if (pid > 0)
{
printf("Parent: I'm the parent, my child's pid is %d.\n", pid);
while (1) // Infinite loop, the parent will never end !
usleep(1);
}
return (0);
}
Now, we can execute our program:

But before we kill the infinite process with ctrl-c, we can open a new terminal and do the ps aux | grep <pid_du_fils> | grep Z+ command to check our zombie out:

Fundamentally, a zombie process isn’t a problem as long as the parent retrieves it. It consumes no energy and takes up no memory space. Zombie processes are also automatically eliminated by their adoptive parent init if they become orphaned. However, if the parent is a process that is never intended to end (server, background process, etc.), that creates children regularly without ever waiting for them, the system’s process table might very well get saturated. That would block the system, which would no longer be able to execute new processes.
Our parent process will need to take better care of its children! It can do this with the wait and waitpid system calls.
The Wait and Waitpid System Calls
In order to suspend the parent process’ execution until the child process’ state changes, we can use the wait or waitpid system calls from the <sys/wait.h> library. Their prototypes are:
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
The difference between the two is especially noticeable when a process has several children. The wait call will retrieve the first terminated child, whereas waitpid holds out for the child matching the PID that we indicated and ignores all of the others. Also, waitpid allows us to specify a few options.
The common parameter to both system calls is:
- status: a pointer to an integer type variable in which
waitandwaitpidcan store the child’s exit status. We will be able to examine this number with different macros to determine if the child finished normally or was interrupted, among other things.
The two extra parameters of waitpid are as follows:
- pid: the PID of the child process we should wait for. The parent process knows this PID because it’s the return value that
forkprovided when the child was created. Alternatively, we can specify -1 in order to wait for whichever child finished first, just likewait(indeed,waitpid(-1, status, 0)is exactly the same aswait(status).) - options:
waitpidoffers several options. Among those, the sometimes very usefulWNOHANG. With theWNOHANGoption,waitpidreturns immediately if the child process has not ended yet. Without this option, the parent process will by default remain suspended as long as the child is still executing its tasks.
If the system call succeeds, both wait and waitpid return the terminated child’s PID, otherwise, they return -1. The waitpid function can also return 0 if the WNOHANG option was specified and if the child it is waiting for has not changed states yet.
Analyzing a Child Process’ Exit Status
The wait and waitpid functions provide us with a status that contains a lot of information about the way in which a child process finished its execution. The status is an integer that represents not only the exit code but also further details that explain why a child exited. So we can easily tell if a child really finished all of its tasks or if it was interrupted.
We can inspect the status thanks to several macros:
WIFEXITED(status): returns true if the child terminated normally, for example by calling exit or finishing through the main function of the program.WEXITSTATUS(status): to be used only ifWIFEXITEDreturned true. Returns the child’s exit code, meaning the number the child specified to the exit function or in the main function’s return.
WIFSIGNALED(status): returns true if the child was forcefully terminated by a signal.WTERMSIG(status): to be used only ifWIFSIGNALEDreturned true. Returns the signal number that provoked the child’s termination.
Example of Wait/Waitpid and Exit Status Analysis
Let’s create a small program that will produce a child process. The child will exit with an exit code that we will define at compilation. The parent process will wait for its child with waitpid (but wait can be used instead) and will then analyze the status it receives.
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <stdio.h>
// Define a macro for a specific child exit code (if we do not
// specify this exit code during compilation with the
// -D CHILD_EXIT_CODE=[number] option), by default, it will be 42:
#ifndef CHILD_EXIT_CODE
# define CHILD_EXIT_CODE 42
#endif
// Define a macro for the expected exit status
#define EXPECTED_CODE 42
// Child process routine:
void child_routine(pid_t pid)
{
printf("\e[36mChild: Hi! I'm the child. PID received from fork = %d\e[0m\n",
pid);
printf("\e[36mChild: Exiting with exit code %d.\e[0m\n",
CHILD_EXIT_CODE);
exit(CHILD_EXIT_CODE);
}
// Parent process routine:
void parent_routine(pid_t pid)
{
int status;
printf("Parent: I'm the parent. PID received from fork = %d\n", pid);
printf("Parent: Waiting for my child with PID [%d].\n", pid);
waitpid(pid, &status, 0); // Wait for child
printf("Parent: My child exited with status %d\n", status);
if (WIFEXITED(status)) // If child exited normally
{
printf("Parent: My child's exit code is %d\n",
WEXITSTATUS(status));
if (WEXITSTATUS(status) == EXPECTED_CODE)
printf("Parent: That's the code I expected!\n");
else
printf("Parent: I was not expecting that code...\n");
}
}
int main(void)
{
pid_t pid; // Store fork's return value
pid = fork(); // Create child process
if (pid == -1)
return (EXIT_FAILURE);
else if (pid == 0) // Child process
child_routine(pid);
else if (pid > 0) // Parent process
parent_routine(pid);
return (EXIT_SUCCESS);
}
We can compile this code with the -D flag to define an exit status for the child to use, like this:
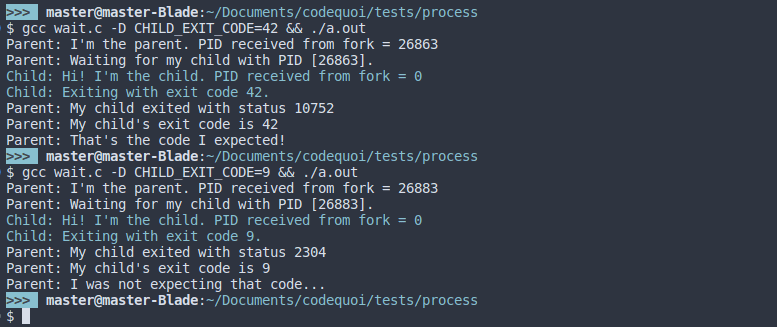
$ gcc wait.c -D CHILD_EXIT_CODE=42 && ./a.out
Here is the result for an exit status of 42 and then 9:
Kill: Terminating Child Processes
It may be a touch sinister, but we can kill our child process if we so desire. To do so, we need to use the kill function of the <signal.h> library to send a signal to the child process that will force it to terminate immediately. The function’s prototype is:
int kill(pid_t pid, int sig);
The parameters we need to supply are:
- pid: the PID of the process that we want to kill.
- sig: the signal that we want to send to the process in order to kill it. There are many different possible signals for kill, each with its own nuances (see man 7 signal), but the most frequently used are perhaps
SIGTERM(soft termination signal) andSIGKILL(hard kill signal).
Le kill functions returns 0 for success and -1 for failure, with errno set to indicate error details. For further details, read this article about signal sending, blocking and intercepting.
Example Usage of Kill
In the following example, we will create three child processes and send them straight into an infinite loop. We will then kill them with a signal and analyze their exits:
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <signal.h>
#include <stdio.h>
// Child process routine:
void child_routine(void)
{
printf("\e[36mChild: Hi! I'm a child. I'm in an infinite loop.\e[0m\n");
while (1) // Infinite loop
continue;
}
// Parent process routine:
void kill_and_get_children(pid_t *pid)
{
int status;
int i;
printf("Parent: I'm the murderous parent.\n");
i = 0;
while (i < 3) // Kill all three children with a signal
{
kill(pid[i], SIGKILL);
i++;
}
printf("Parent: I killed all my children! Mwahahaaa!\n");
i = 0;
while (i < 3) // Wait for each child and get its exit status
{
waitpid(pid[i], &status, 0);
if (WIFEXITED(status))
printf("Parent: Child [%d] terminated normally.\n", pid[i]);
else if (WIFSIGNALED(status))
{
printf("Parent: Child [%d] was interrupted.\n", pid[i]);
if (WTERMSIG(status) == SIGTERM)
printf("\e[31mParent: Child [%d] got the %d signal, SIGTERM\e[0m\n",
pid[i], WTERMSIG(status));
if (WTERMSIG(status) == SIGKILL)
printf("\e[31mParent: Child [%d] got the %d signal, SIGKILL\e[0m\n",
pid[i], WTERMSIG(status));
}
i++;
}
}
int main(void)
{
pid_t pid[3]; // Store fork's return values
int i;
i = 0;
while (i < 3) // Create 3 children
{
pid[i] = fork(); // Create a child
if (pid[i] == -1)
return (EXIT_FAILURE);
else if (pid[i] == 0)
child_routine();
else if (pid[i] > 0)
printf("Parent: Child #%d created with pid = %d\n", i, pid[i]);
usleep(1000); // Delay next child's creation
i++;
}
kill_and_get_children(pid);
return (EXIT_SUCCESS);
}
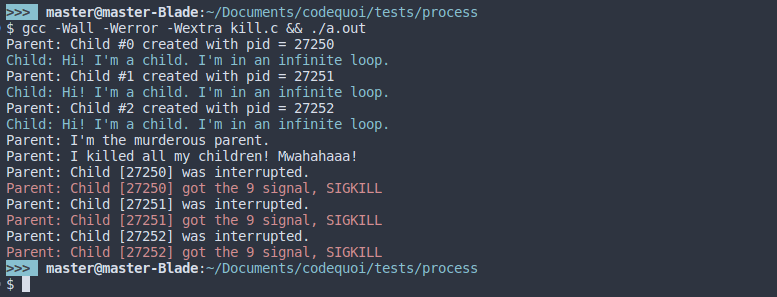
Here, we can see that the second the termination signal arrives, the child processes stop immediately. The parent process who is waiting for them receives their status and can analyze it to see exactly which signal was used to kill them. If we simply change the signal we send with kill, we’ll get a different result.
Tips for Debugging a Program with Child Processes
A good program should have no memory leaks. If the program creates child processes, none of its child processes should have memory leaks either. So we need to make sure to free all allocated memory at the end of each of our program’s processes. If we kill our child processes with a signal, we should beware of which signal we choose: SIGTERM, SIGINT and SIGKILL don’t all have the same implications as far as memory leaks are concerned!
Debugging a program that creates child processes can be pretty overwhelming. In particular, Valgrind will probably output a torrent of error messages, coming not only from the parent process but also from every child process. Thankfully, Valgrind offers the option to mute the errors coming from child processes: --child-silent-after-fork=yes. Once the parent process’ errors resolved, we can remove this option to check the errors coming from the children.
A little tip to share, a nagging question to ask, or a strange discovery to discuss about child processes? I’d love to read and respond to it all in the comments. Happy coding !
Sources and Further Reading
-
Linux Programmer’s Manual:
-
Wikipedia, init [wikipedia.org]
-
Geeks for Geeks, fork() in C [geeksforgeeks.org]
-
Aline, Les processus zombies [it-connect.fr]
-
Tecmint, All You Need To Know About Processes in Linux [tecmint.com]