Manipuler un fichier à l'aide de son descripteur en C
- Mia Combeau
- C
- 26 octobre 2022
Table des matières
Les appels systèmes disponibles en C pour créer ou ouvrir un fichier, le lire, y écrire et le supprimer font toutes usage d’un descripteur de fichier. Avant de pouvoir manipuler des fichiers, nous devons donc découvrir comment le système d’exploitation gère ses références à ces fichiers.
Qu’est-ce qu’un descripteur de fichier ?
Sur un système de type Unix, un descripteur de fichier (ou file descriptor en anglais, souvent abrégé fd) est un petit entier positif qui fait référence à un fichier ouvert par un processus. Un processus, comme on l’a vu dans un précédent article sur les processus, c’est un programme en cours d’exécution.
Mais un fichier, du point de vue du système d’exploitation, ce n’est pas uniquement un fichier texte comme on peut l’entendre en tant qu’utilisateur. Un fichier peut aussi être un répertoire ou même un autre périphérique d’entrée/sortie comme un clavier ou un écran, ou encore un pipe ou une socket réseau.
Par défaut, chaque processus hérite systématiquement de trois descripteurs de fichiers ouverts :
| Descripteur de fichier | Nom | <unistd.h> |
<stdio.h> |
|---|---|---|---|
0 |
Entrée standard | STDIN_FILENO |
stdin |
1 |
Sortie standard | STDOUT_FILENO |
stdout |
2 |
Erreur standard | STDERR_FILENO |
stderr |
Mais pourquoi utiliser des descripteurs de fichiers comme identifiants ? Un entier, c’est déjà bien plus simple `a traiter pour un ordinateur qu’une longue chaîne de caractères contenant le chemin vers un fichier. Sans compter que la référence à un fichier doit contenir bien plus que l’endroit où il se trouve : il faut aussi connaître ses permissions, son mode d’accès, sa taille, etc… De plus, il serait peu économique de garder en mémoire plusieurs références entières à propos d’un fichier si plusieurs processus l’ont ouvert.
Alors comment le système d’exploitation maintient-il toutes ces informations à propos des fichiers ouverts ?
La représentation des fichiers ouverts sur le système
Pour représenter les fichiers ouverts, le système utilise trois structures de données :
- Une table de descripteurs de fichiers par processus. Chaque processus possède sa propre table qui contient une suite d’indexes, chacun faisant référence à une entrée dans la table des fichiers ouverts.
- Une table des fichiers ouverts qui est commune à tous les processus. Chaque entrée de ce tableau contient, entres autres, le mode d’accès, la tête de lecture du fichier, et un pointeur vers l’entrée correspondante dans la table inode. Cette table garde aussi un compte du nombre de références à ce fichier dans toutes les tables de descripteurs de tous les processus. Lorsqu’un processus ferme le fichier, ce compte est décrémenté et s’il arrive à 0, l’entrée est supprimée de la table des fichiers.
- Et enfin, une table inode ( index node) qui est aussi commune à tous les processus. Chaque entrée dans la table inode décrit en détail le fichier en question : le chemin où il se trouve sur le disque dur, sa taille, ses permissions, etc.

Ce diagramme démontre l’organisation des références aux fichiers utilisés par trois processus.
Deux processus peuvent bien sûr ouvrir le même fichier : le processus A peut accéder au fichier B via son descripteur 4 et de même pour le processus B avec son descripteur 3. Ce fait peut donc faciliter la communication inter-processus.
De plus, un processus peut aussi avoir deux références au même fichier, comme c’est le cas pour le processus C. Ceci peut se produire lorsqu’on ouvre deux fois le même fichier. Nous verrons pourquoi une telle chose pourrait se révéler utile plus loin.
Open : ouvrir ou créer un fichier en C
Pour manipuler un fichier en C, on doit d’abord informer le système d’exploitation de nos intentions avec la fonction open de la bibliothèque <fcntl.h>. Cet appel système nous permet d’ouvrir un fichier existant, ou de créer le fichier s’il n’existe pas déjà. Il faut au minimum préciser le chemin vers le fichier à ouvrir ainsi que le mode d’accès :
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
Il y a donc deux versions de l’appel système open. Voici leurs paramètres :
- pathname : le chemin vers le fichier sous forme de chaîne de caractères,
- flags : un entier qui représente les drapeaux qui indiquent le mode d’accès, et que nous examinerons ci-dessous,
- mode : un entier qui représente les permissions à donner au fichier. Ceci est un paramètre “optionnel” qui sera ignoré s’il est spécifié et qu’on ne demande pas à créer le fichier dans le cas où il n’existe pas déjà.
La fonction open renvoie un nouveau descripteur de fichier si le fichier a bien pu être ajouté à la table inode et celle des fichiers ouverts. Le descripteur de fichier sera typiquement plus grand que 2, les fd 0, 1, et 2 étant réservés à l’entrée et aux sorties standard. Par contre, en cas d’erreur, par exemple, si on demande à ouvrir un fichier qui n’existe pas sans l’option de création, ou pour lequel on n’a pas les permissions, la fonction open renverra -1.
Le mode d’accès au fichier dans open
Le paramètre flags de l’appel système open nous permet de choisir le mode d’accès au fichier. La bibliothèque <fcntl.h> contient une grande sélection de constantes symboliques (voir la liste entière dans la page de manuel de open). Parmi elles, les plus courantes sont :
| Constante symbolique | Description |
|---|---|
O_RDONLY |
Lecture seule |
O_WRONLY |
Écriture seule |
O_RDWR |
Lecture et écriture |
O_TRUNC |
Ouverture du fichier en mode tronqué. Si le fichier existe est le mode d’accès permet d’y écrire ( O_WRONLY ou O_RDWR), tronque son contenu à une taille de 0 à l’ouverture, avec l’effet d’écraser son contenu. |
O_APPEND |
Ouverture du fichier en mode ajout. La tête d’écriture est positionnée à la fin du ficher à chaque écriture avec pour effet d’ajouter du texte à la fin du ficher au lieu de l’écraser. |
O_CREAT |
Créé le fichier s’il n’existe pas. Il faut alors indiquer ses permissions dans le paramètre mode de open. |
Par exemple, on peut ouvrir un fichier en mode lecture seule de cette façon :
open("chemin/vers/fichier", O_RDONLY);
Mais on peut aussi cumuler les drapeaux avec l’opérateur bitwise | (OU). Par exemple, si on voulait ouvrir un fichier en mode écriture seule et tronqué, on pourrait faire :
open("chemin/vers/fichier", O_WRONLY | O_TRUNC);
Notons aussi qu’il est obligatoire d’indiquer le mode d’accès avec soit O_RDONLY, soit O_WRONLY soit O_RDWR. On ne peut pas, par exemple, spécifier O_CREAT sans autre indication du mode d’accès.
Créer un fichier avec l’option O_CREAT d’open
On l’a vu précédemment, open nous permet aussi de créer un fichier si le fichier spécifié n’existe pas déjà. Il faut pour cela lui spécifier la constante O_CREAT dans son paramètre des flags. Dans ce cas, on doit impérativement lui indiquer dans le paramètre optionnel suivant, mode, les permissions du nouveau fichier.
| Constante symbolique | Décimal | Description |
|---|---|---|
S_IRWXU |
700 | Le propriétaire (user) a les permissions de lecture, d’écriture et d’exécution |
S_IRUSR |
400 | Le propriétaire a la permission de lecture |
S_IWUSR |
200 | Le propriétaire a la permission d’écriture |
S_IXUSR |
100 | Le propriétaire a la permission d’exécution |
S_IRWXG |
070 | Le groupe a les permissions de lecture, d’écriture et d’exécution |
S_IRGRP |
040 | Le groupe a la permission de lecture |
S_IWGRP |
020 | Le groupe a la permission d’écriture |
S_IXGRP |
010 | Le groupe a la permission d’exécution |
S_IRWXO |
007 | Les autres utilisateurs (others) ont les permissions de lecture, d’écriture et d’exécution |
S_IROTH |
004 | Les autres utilisateurs ont la permission de lecture |
S_IWOTH |
002 | Les autres utilisateurs ont la permission d’écriture |
S_IXOTH |
001 | Les autres utilisateurs ont la permission d’exécution |
On remarquera que ces nombres encodés dans ces constantes symboliques sont exactement les mêmes que ceux qu’on peut utiliser avec la commande chmod pour changer les permissions d’un fichier.
Bien évidemment, on peut aussi combiner ces constantes symboliques avec le même opérateur bitwise OU que pour le mode d’accès. Par exemple, pour créer un fichier en mode écriture seule et ajout avec les permissions de lecture et d’écriture pour le propriétaire et seulement lecture pour le groupe :
open("chemin/vers/fichier", O_WRONLY | O_APPEND | O_CREAT, S_IRUSR | S_IWUSR | S_IRGRP);
Une alternative pour raccourcir cette spécification des permission est d’utiliser directement leur valeurs numériques additionnées précédées d’un 0. Ceci est exactement équivalent à l’exemple précédent :
open("chemin/vers/fichier", O_WRONLY | O_APPEND | O_CREAT, 0640);
Close : fermer un descripteur de fichier en C
Lorsqu’on a terminé de manipuler un fichier, on doit bien sûr le fermer et déréférencer le descripteur de fichier à l’aide de l’appel système close de la bibliothèque <unistd.h>. Son prototype ne pourrait être plus simple :
int close(int fd);
On lui fournit un descripteur de fichier en paramètres et le système se charge de le déréférencer et, si aucun autre processus n’a ouvert ce fichier, de le supprimer de ses tables de fichiers ouverts et inode. En cas de succès, la fonction close renvoie 0, mais en cas d’erreur, elle renvoie -1 et met errno à jour.
Toutefois, la fonction close ne fait que fermer le descripteur de fichier. Il ne le supprime pas ! Ça, c’est la prérogative de la fonction unlink.
Unlink : supprimer un fichier en C
Si l’on souhaite supprimer entièrement un fichier sur le disque dur depuis un programme en C, on peut utiliser l’appel système unlink de la bibliothèque <unistd.h>. Son prototype est :
int unlink(const char *pathname);
On a juste à lui fournir le chemin vers le fichier et il sera supprimé lorsque tous les processus qui l’utilisent auront fermé leurs descripteurs qui lui font référence avec close. Cet appel système renvoie 0 s’il réussit ou -1 s’il rencontre une erreur.
Bien entendu, rien ne sert de fermer et de supprimer un fichier juste après l’avoir ouvert : on veut sans doute faire quelque chose de ce fichier ouvert. Pourquoi pas y écrire ?
Write : écrire vers un descripteur de fichier en C
Une fois un descripteur de fichier ouvert avec un mode d’accès qui permet l’écriture, on va pouvoir écrire dedans grâce à l’appel système write de la bibliothèque <unistd.h>. Son prototype est le suivant :
ssize_t write(int fd, const void *buf, size_t count);
Et ses paramètres sont :
- fd : un descripteur de fichier où écrire,
- buf : un pointeur vers l’espace mémoire à écrire dans le fichier, typiquement, ce sera une chaîne de caractères,
- count : le nombre d’octets (c’est à dire de caractères) à écrire, typiquement, ce sera la longueur de la chaîne de caractères spécifiée dans le précédent paramètre.
En cas de réussite, la fonction write renvoie le nombre d’octets qui ont été écrits. Par contre en cas d’erreur elle renvoie -1 et met errno à jour pour indiquer l’erreur.
Faisons un petit test pour s’assurer du fonctionnement de open, write et close :
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main(void)
{
int fd;
// Ouvre un descripteur de fichier pour le fichier "test.txt"
// En mode écriture seule, tronquée et crée le fichier s'il
// n'existe pas. Permissions de lecture et d’écriture pour le
// propriétaire et de lecture pour le groupe.
fd = open("test.txt", O_WRONLY | O_TRUNC | O_CREAT, 0640);
// S'il y a eu un problème, on arrête tout
if (fd == -1)
return (1);
// Imprime le fd du nouveau fichier ouvert
printf("fd = %d\n", fd);
// Écrit dans le fichier
write(fd, "Hello World!\n", 13);
// Ferme le fichier
close(fd);
return (0);
}
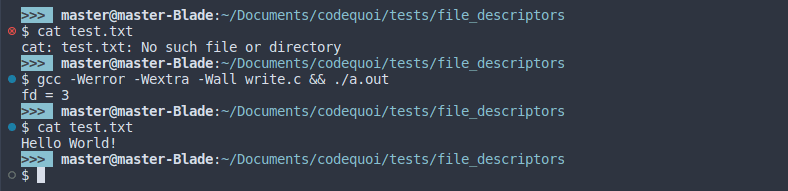
Dans ce résultat, on peut voir que le fichier test.txt a bien été crée puisqu’il n’existait pas avant qu’on lance le programme. De plus, il contient bien la phrase qu’on a écrite avec write.
Si l’on souhaite ajouter du texte à un fichier au lieu d’écraser son contenu, il faut se souvenir que cela ne relève pas de la responsabilité de la fonction write. C’est le mode d’accès spécifié dans la fonction open ( O_TRUNC ou O_APPEND) qui contrôle où et comment write écrit dans le fichier.
Read : lire depuis un descripteur de fichier en C
La fonction read, de la bibliothèque <unistd.h>, charge en mémoire le contenu d’un fichier, en partie ou en entier, grâce à son descripteur de fichier. Voici son prototype :
ssize_t read(int fd, void *buf, size_t count);
Les paramètres de la fonction read sont les suivants :
- fd : le descripteur de fichier depuis lequel on veut lire,
- buf : un pointeur vers une zone mémoire où temporairement stocker les caractères lus,
- count : une taille en octets à lire, autrement dit, le nombre de caractères à lire. Cette taille correspondra souvent à la taille de la zone mémoire fournie dans le précédent paramètre.
Puis, la fonction read renvoie le nombre de caractères qu’elle a lu, ou -1 en cas d’erreur. Quand la lecture avec read atteint la fin du fichier, elle va naturellement renvoyer 0.
La fonction read s’arrête donc de lire dès qu’elle atteint le nombre de caractères qu’on lui indique ou la fin du fichier (EOF, end of file).
Tentons donc d’ouvrir un fichier en lecture seule et d’y lire 100 caractères à la fois jusqu’à la fin du fichier :
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#define BUFFER_SIZE 100
int main(void)
{
char buf[BUFFER_SIZE + 1]; // stocke les caractères lus par read
int fd; // descripteur de fichier à lire
int nb_read; // stocke le retour de read
int count; // compte du nombre de lectures avec read
// Ouvre le fichier cat.txt en mode lecture seule
fd = open("cat.txt", O_RDONLY);
if (fd == -1)
return (1);
// Initialise les variables de compte
nb_read = -1;
count = 0;
// Boucle tant que read ne retourne pas 0 (ce qui veut dire
// qu'il n'y a plus rien à lire dans le fichier)
while (nb_read != 0)
{
// Lecture de 100 caractères avec read depuis le
// descripteur de fichier ouvert
nb_read = read(fd, buf, BUFFER_SIZE);
// En cas d'erreur, read renvoie -1, on arrête tout
if (nb_read == -1)
{
printf("Erreur de lecture !\n");
return (1);
}
// Read n'ajoute pas le \0 à la fin de la chaîne
// de caractères lus. On peut se servir du nombre
// de caractères lus comme index du dernier caractère
buf[nb_read] = '\0';
// Imprime ce que contient le buffer après la lecture
printf("\e[36m%d : [\e[0m%s\e[36m]\e[0m\n", count, buf);
count++;
}
// Ferme le descripteur de fichier ouvert plus tôt
close(fd);
return (0);
}
Le fichier cat.txt contiendra un extrait de Wikipédia (en anglais pour ne pas fausser le compte de caractères avec tous nos accents français !) :
The cat (Felis catus) is a domestic species of small carnivorous mammal. It is the only domesticated species in the family Felidae and is commonly referred to as the domestic cat or house cat to distinguish it from the wild members of the family. A cat can either be a house cat, a farm cat, or a feral cat; the latter ranges freely and avoids human contact. Domestic cats are valued by humans for companionship and their ability to kill rodents. About 60 cat breeds are recognized by various cat registries.
À l’exécution, ce code donne :

La fonction read a bien l’air d’avoir un marque-pages intégré ! A chaque appel, read reprend la lecture là où elle s’est arrêtée la dernière fois. En réalité, la fonction read ne retient pas elle-même sa dernière position dans le fichier : elle incrémente la tête de lecture du descripteur de fichier.
La tête de lecture d’un descripteur de fichier
Comme on l’aura peut-être remarqué dans le schéma au début de cet article, les références dans la table commune des fichiers ouverts contient une tête de lecture. Celle-ci contrôle le décalage entre le début du fichier et la position actuelle à l’intérieur du fichier. Et c’est elle que read incrémente à la fin de sa lecture. La tête de lecture est simplement appelée " offset" en anglais.
Donc quand on ouvre un fichier, la tête de lecture est typiquement à 0, ce qui veut dire qu’on se trouve en tout début de fichier. Quand on lit, disons, 12 caractères avec read, la tête de lecture est mise à jour à 12. La prochaine fois qu’on accède au descripteur de fichier pour y lire ou même y écrire, on commencera depuis la position du début du fichier décalé de la valeur de la tête de lecture, ici donc, au 13ème caractère.
Notons aussi que malgré son nom, la tête de lecture est aussi la tête d’écriture : la fonction write sera aussi affectée par tout déplacement de la tête dans le fichier.
Alors comment pouvons-nous déplacer cette tête de lecture, pour, par exemple, retourner au tout début du fichier après y avoir lu ?
Retrouver le début du fichier avec un nouveau descripteur
La solution la plus simple est sans doute d’ouvrir à nouveau le même fichier avec open. Cela crée une nouvelle entrée dans le tableau des fichiers ouverts du système sans aucun décalage de tête de lecture.
Testons cette théorie en modifiant un peu notre programme précédent. On ouvrira le même fichier deux fois pour avoir deux références, puis on lira depuis le premier descripteur de fichier, puis le deuxième :
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#define BUFFER_SIZE 100
void read_and_print_100(int fd)
{
char buf[BUFFER_SIZE + 1]; // stocke les caractères lus par read
int nb_read; // stocke le retour de read
// Lit 100 caractères du fichier
nb_read = read(fd, buf, BUFFER_SIZE);
// En cas d'erreur, on arrête tout
if (nb_read == -1)
{
printf("Erreur de lecture !\n");
return ;
}
// Ajoute le \0 à la fin de la chaîne
buf[nb_read] = '\0';
// Imprime ce que contient le buffer après la lecture, précédé
// du déscripteur de fichier d'où provient le contenu
printf("\e[36mfd %d : [\e[0m%s\e[36m]\e[0m\n", fd, buf);
return ;
}
int main(void)
{
int fd1; // descripteur de fichier à lire
int fd2; // second descripteur de fichier à lire
// Ouvre le fichier cat.txt en mode lecture seule
fd1 = open("cat.txt", O_RDONLY);
// Ouvre à nouveau le fichier cat.txt en mode lecture seule
fd2 = open("cat.txt", O_RDONLY);
if (fd1 == -1 || fd2 == -1)
return (1);
// Imprime les 100 premiers caractères du descripteur 1
read_and_print_100(fd1);
// Imprime les 100 prochains caractères du descripteur 1
read_and_print_100(fd1);
// Imprime les 100 premiers caractères du descripteur 2
read_and_print_100(fd2);
// Ferme les descripteurs de fichier ouverts plut tôt
close(fd1);
close(fd2);
return (0);
}

Comme on peut le voir dans ce résultat, on a deux descripteurs de fichiers, 3 et 4, qui font référence au même fichier, cat.txt. On lit 100 caractères deux fois depuis le descripteur 3 ce qui veut dire qu’on met la tête de lecture à 200. Ensuite, quand on lit depuis le descripteur 4 auquel on n’a pas encore touché, on reçoit de nouveau les 100 premiers caractères du fichier. Cela montre bien que même s’ils font référence au même fichier, les deux descripteurs sont distincts : le déplacement de la tête de lecture de l’un n’affecte pas l’autre.
Lseek : repositionner la tête de lecture
Une autre option pour repositionner la tête de lecture à l’endroit qu’on veut, c’est la fonction lseek de la bibliothèque <unistd.h>. Elle nous permet d’exercer un contrôle plus précis sur la position de la tête de lecture. Son prototype est :
off_t lseek(int fd, off_t offset, int whence);
Regardons ses paramètres de plus près :
- fd : le descripteur de fichier pour lequel repositionner la tête de lecture,
- offset : le décalage en octets souhaité pour la tête de lecture,
- whence : par rapport à quel endroit appliquer le décalage. Les options possibles ici sont :
SEEK_SET: appliquer le décalage par rapport au début du fichier (écrase la valeur de la tête de fichier avec celle fournie dans le précédent paramètre),SEEK_CUR: appliquer le décalage par rapport à la position actuelle (ajoute l’offset spécifié à la tête de lecture actuelle),SEEK_END: appliquer le décalage par rapport à la fin du fichier (ajoute l’offset à la fin du fichier).
Il faut faire attention avec lseek car cette fonction nous permet de mettre notre tête de lecture au-delà de la fin du fichier ! Si l’on écrit après la fin du fichier, sa taille ne changera pas et cela pourrait créera des “trous”, des zones remplies de \0 au milieu du fichier. Voir la page manuel de lseek pour plus d’informations à ce sujet.
Si lseek réussit, elle renvoie le nouveau décalage, le nombre total d’octets depuis le début du fichier. En cas d’échec, elle renvoie -1 et met errno à jour pour contenir le code d’erreur.
Ouvrons donc de nouveau notre fichier pour y lire 100 caractères, puis expérimentons avec lseek pour déplacer la tête de lecture du fichier entre deux lectures :
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#define BUFFER_SIZE 100
void read_and_print_100(int fd)
{
char buf[BUFFER_SIZE + 1]; // stocke les caractères lus par read
int nb_read; // stocke le retour de read
// Lit 100 caractères du fichier
nb_read = read(fd, buf, BUFFER_SIZE);
// En cas d'erreur, on arrête tout
if (nb_read == -1)
{
printf("Erreur de lecture !\n");
return ;
}
// Ajout du \0 à la fin de la chaîne
buf[nb_read] = '\0';
// Imprime ce que contient le buffer après la lecture, précédé
// du descripteur de fichier d'où provient le contenu
printf("\e[36mfd %d : [\e[0m%s\e[36m]\e[0m\n", fd, buf);
return ;
}
int main(void)
{
int fd; // descripteur de fichier à lire
// Ouvre le fichier cat.txt en mode lecture seule
fd = open("cat.txt", O_RDONLY);
if (fd == -1)
return (1);
// Imprime les 100 premiers caractères du descripteur
read_and_print_100(fd);
// Déplace la tête de lecture au début du fichier
lseek(fd, 0, SEEK_SET);
read_and_print_100(fd);
// Déplace la tête de lecture à 4 caractères du début du fichier
lseek(fd, 4, SEEK_SET);
read_and_print_100(fd);
// Déplace la tête de lecture 1 caractère plus loin
lseek(fd, 1, SEEK_CUR);
read_and_print_100(fd);
// Déplace la tête de lecture à la fin du fichier
lseek(fd, 0, SEEK_END);
read_and_print_100(fd);
// Ferme le descripteur de fichier ouvert plut tôt
close(fd);
return (0);
}

Dup et dup2 : dupliquer des descripteurs de fichier
Parfois, il est utile de dupliquer un descripteur de fichier afin d’en faire la sauvegarde ou d’en remplacer un autre. C’est le cas, par exemple, dans le contexte d’une redirection de l’entrée ou de la sortie standard vers un fichier.
Ce sont les appels système dup et dup2 de la bibliothèque <unistd.h> qui vont nous permettre de dupliquer un descripteur de fichier. Voici leurs prototypes :
int dup(int oldfd);
int dup2(int oldfd, int newfd);
Tous deux prennent en paramètre le descripteur qu’on veut dupliquer ( oldfd) et renvoient le nouveau descripteur de fichier, ou -1 en cas d’échec. La différence entre les deux c’est que dup choisit automatiquement le plus petit numéro inutilisé pour le nouveau descripteur de fichier, tandis qu’avec dup2, on peut spécifier le numéro qu’on veut ( newfd).
Il faut garder à l’esprit que dup2 va tenter de fermer le newfd s’il est utilisé avant de le transformer en une copie de oldfd. Cependant, si oldfd n’est pas un descripteur de fichier valide, l’appel va échouer et newfd ne sera pas fermé. Si newfd et oldfd sont identiques et valides, dup2 renverra newfd sans rien faire d’autre.
L’interchangeabilité des descripteurs dupliqués
Après un appel réussi à dup ou dup2, l’ancien et le nouveau descripteurs sont interchangeables : ils font référence au même fichier dans la table des fichiers ouverts et partagent donc tous ses attributs. Par exemple, si on lit avec read les premiers caractères de l’un des descripteurs, la tête de lecture va être modifiée. Et ce, pour les deux descripteurs de fichier, pas seulement celui avec lequel on a lu.
Pourtant, on a vu précédemment que si l’on rouvrait le même fichier une deuxième fois, les deux descripteurs ne se partageaient pas la tête de lecture de cette façon. Alors pourquoi cela fonctionne-t-il différemment pour les descripteurs dupliqués ? La raison se schématise bien comme ceci :

Un descripteur de fichier ouvert possède sa propre entrée dans le tableau des fichiers ouverts, avec sa propre tête de lecture. Par contre, un descripteur de fichier dupliqué pointe vers la même entrée dans la table des fichiers ouverts, ce qui implique qu’il partage la tête de lecture de son clone.
Exemple d’usage de dup/dup2
Dans l’exemple suivant, on va ouvrir un fichier alpha.txt, qui contient simplement l’alphabet, puis dupliquer le descripteur de fichier ouvert avec dup. On va lire depuis le descripteur, puis depuis la copie de de descripteur. Ensuite, on dupliquera encore une fois le descripteur sur l’entrée standard (fd 0) avec dup2. Enfin, on va créer une boucle infinie pour nous donner le temps d’aller regarder les descripteurs de fichier ouverts dans notre processus.
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
int main(void)
{
int fd;
int fd_copy;
int nb_read;
char buf[15];
// Imprime le PID de notre processus pour pouvoir regarder
// les fd ouverts par ce processus
printf("Mon PID est %d\n", getpid());
// Recupère un fd en ouvrant un fichier
fd = open("alpha.txt", O_RDONLY);
if (fd == -1)
return (1);
// Duplique ce fd sur le fd inutilisé
// le plus petit
fd_copy = dup(fd);
if (!fd_copy)
return (1);
// Lit le fd ouvert
nb_read = read(fd, buf, 10);
if (nb_read == -1)
return (1);
buf[nb_read] = '\0';
printf("fd %d contient : %s\n", fd, buf);
// Lit le fd dupliqué
nb_read = read(fd_copy, buf, 10);
if (nb_read == -1)
return (0);
buf[nb_read] = '\0';
printf("fd %d contient : %s\n", fd_copy, buf);
// Duplique le descripteur sur l'entrée standard
dup2(fd, STDIN_FILENO);
// Boucle infinie pour pouvoir aller voir les fd ouverts
// par ce processus avec ls -la /proc/PID/fd
while (1)
;
}
Le fichier alpha.txt contient :
ABCDEFGHIJKLMNOPQRSTUVWXYZ
Résultat du programme :
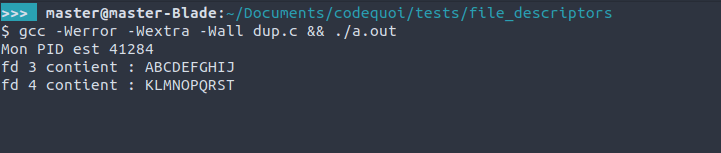
Ici, on peut voir que la lecture du premier descripteur de fichier a bien changé la tête de lecture de sa copie aussi. Avant de tuer notre processus avec ctrl-c, on va ouvrir un autre terminal pour aller voir la liste des descripteurs de fichier ouverts par notre processus avec la commande :
$ ls -la /proc/PID/fd
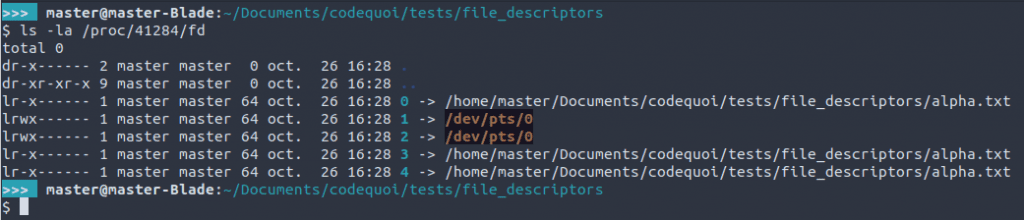
On peut voir que les descripteurs 3 et 4 font maintenant bien tous deux référence à notre fichier alpha.txt, mais pas seulement ! L’entrée standard (fd 0) a aussi été redirigée vers notre fichier grâce à dup2.
Une autre astuce à partager, une petite question à poser, ou une découverte intéressante à propos de la manipulation de fichiers et de descripteurs en C ? Je serai ravie de lire et de répondre à tout ça dans les commentaires. Bon code !
Sources et lectures supplémentaires
-
Manuel du programmeur Linux :
-
Bryant, R. E., O’Hallaron, D. R., 2016, Computer Systems: A Programmer’s Perspective, Chapter 10: System-Level I/O, pp. 925-949
-
Kernighan, B. W., Ritchie, D. M., 1988, The C Programming Language, Second Edition, Chapter 8 - The UNIX System Interface, pp. 169-175
-
Simard, E., Everything You Need to Know About inodes in Linux [linuxhandbook.com]