Threads, mutex et programmation concurrente en C
- Mia Combeau
- C
- 2 novembre 2022
Table des matières
Par souci d’efficacité ou par nécessité, un programme peut être construit de façon concurrente et non séquentielle. Grâce à sa programmation concurrente et `a l’aide de ses processus fils ou de ses threads et de ses mutex, il pourra effectuer plusieurs tâches simultanément.
Dans un précédent article, nous avons pu comprendre comment créer des processus fils, qui sont une manière d’implémenter la programmation concurrente. Nous nous concentrerons ici sur threads, et comment faire face aux dangers de leur mémoire partagée à l’aide de mutex.
La programmation concurrente
Par opposition à la programmation séquentielle, la programmation concurrente permet à un programme d’effectuer plusieurs tâches simultanément au lieu de devoir attendre la fin d’une opération pour commencer la suivante. Le système d’exploitation lui-même utilise ce concept pour pouvoir répondre aux attentes de l’utilisateur. Si on devait attendre la fin d’une chanson pour pouvoir ouvrir notre navigateur, ou si on devait redémarrer l’ordinateur pour tuer un programme pris dans une boucle infinie, on mourrait de frustration !
Il existe trois façons d’implémenter la concurrence dans nos programmes : les processus, les threads et le multiplexage. Concentrons-nous ici sur les threads.
Qu’est-ce qu’un thread ?
Un thread (ou un fil d’exécution en français), c’est une suite logique d’instructions à l’intérieur d’un processus qui est automatiquement gérée par le noyau du système d’exploitation. Un programme séquentiel consiste en un seul thread. Mais les systèmes d’exploitation modernes nous permettent d’accommoder plusieurs threads dans nos programmes, qui se déroulent tous en parallèle.
Chaque thread d’un processus possède son propre contexte : son identifiant unique, sa pile d’exécution ou stack, son pointeur d’instruction, son registre de processeur. Mais comme tous les threads font partie du même processus, ils partagent le même espace d’adressage virtuel : le même code, la même heap, les mêmes bibliothèques partagées et les mêmes descripteurs de fichiers ouverts.
Le contexte d’un thread est plus petit que celui d’un processus en termes de ressources. Il est donc bien plus rapide pour le système de créer un thread que de créer un processus. Passer d’un thread à l’autre est aussi plus expéditif que de passer d’un processus à l’autre.
Les threads n’ont pas non plus la stricte hiérarchie père-fils des processus. Ils forment plutôt un ensemble de pairs qui ne dépend pas de quel thread a créé quel autre thread. Le thread “principal” a pour seule distinction d’avoir été le premier à exister au démarrage du processus. Cela veut dire que n’importe quel thread peut tuer ou attendre la fin de n’importe quel autre thread dans le même processus.
De plus, chaque thread peut lire et écrire sur la même mémoire virtuelle, ce qui rend la communication entre threads bien plus aisée que la communication entre processus. Cependant, nous étudierons plus tard les problèmes qui peuvent survenir de cette mémoire partagée.
Utiliser les Threads POSIX
En C, l’interface standard pour manipuler les threads est POSIX avec la bibliothèque <pthread.h>. Celle-ci comprend une soixantaine de fonctions qui permettent de créer et récupérer des threads, ainsi que pour gérer les données entre eux. On n’en verra que quelques unes dans cet article. Pour compiler un programme qui fait usage de cette bibliothèque, il ne faut pas oublier de la lier avec -pthread :
gcc -pthread main.c
Créer un thread
On peut créer un nouveau thread depuis n’importe quel thread du programme avec la fonction pthread_create, dont le prototype est le suivant :
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void *),
void *restrict arg);
Examinons chaque argument qu’on doit lui fournir :
- thread : un pointeur vers une variable de type
pthread_tpour stocker l’identifiant du thread qu’on va créer. - attr : un argument qui permet de changer les attributs par défaut du nouveau thread lors de sa création. Ceci va au-delà de la portée de cet article, et en général il suffira d’indiquer
NULLici. - start_routine : la fonction par laquelle le thread commence son exécution. Cette fonction doit avoir pour prototype
void *nom_de_fonction_au_choix(void *arg);. Lorsque le thread arrive à la fin de cette fonction, il aura terminé toutes ses tâches. - arg : le pointeur vers un argument à transmettre à la fonction
start_routinedu thread. Si l’on souhaite passer plusieurs paramètres à cette fonction, il n’y a pas d’autre choix que de lui renseigner ici un pointeur vers une structure de données.
Lorsque la fonction pthread_create termine, la variable thread qu’on lui a fournie contiendra l’identifiant du thread créé. Le fonction elle-même renvoie 0 si la création s’est bien passée, ou un code erreur dans le cas contraire.
Récupérer un thread ou le détacher
Pour bloquer l’exécution d’un thread en attendant qu’un autre thread se termine, on peut utiliser la fonction pthread_join :
int pthread_join(pthread_t thread, void **retval);
Ses paramètres sont les suivants :
- thread : l’identifiant du thread qu’on attend. Le thread spécifié ici doit être joignable (c’est à dire non détaché - voir ci-dessous).
- retval : un pointeur vers une variable qui peut contenir la valeur de retour de la fonction routine du thread (la fonction
start_routinequ’on a fournie lors de la création du thread). Si on n’a pas besoin de cette valeur, on peut simplement renseignerNULL.
La fonction pthread_join renvoie 0 en cas de succès, ou dans le cas contraire, un code erreur.
On remarquera qu’on ne peut qu’attendre la fin d’un thread spécifique. Il n’y a aucun moyen d’attendre le premier thread qui se termine sans s’occuper de son identifiant, comme le fait la fonction wait avec les processus fils.
Mais dans certains cas, il est possible et préférable de ne pas s’occuper d’attendre la fin de certains threads. On peut alors détacher le thread pour indiquer au système qu’il peut récupérer ses ressources dès que le thread termine. Pour cela, on utilise la fonction pthread_detach (généralement juste après la création du thread) :
int pthread_detach(pthread_t thread);
Ici, on a simplement à renseigner l’identifiant du thread. On reçoit en retour 0 si le détachement s’est bien passé, ou un code erreur. Après l’avoir détaché, les autres threads n’auront ni la possibilité de tuer ce thread ni celle d’attendre de le récupérer avec pthread_join.
Exemple pratique de fonctionnement de threads
Écrivons un petit programme très simple qui crée deux threads pour ensuite les récupérer. La routine de chaque thread consistera simplement à imprimer son identifiant accompagné d’une citation philosophique de Victor Hugo.
#include <stdio.h>
#include <pthread.h>
# define NC "\e[0m"
# define YELLOW "\e[1;33m"
// thread_routine est la fonction que le thread invoque directement
// après sa création. Le thread se termine à la fin de cette fonction.
void *thread_routine(void *data)
{
pthread_t tid;
// La fonction pthread_self() renvoie
// l'identifiant propre à ce thread.
tid = pthread_self();
printf("%sThread [%ld]: Le plus grand ennui c'est d'exister sans vivre.%s\n",
YELLOW, tid, NC);
return (NULL); // Le thread termine ici.
}
int main(void)
{
pthread_t tid1; // Identifiant du premier thread
pthread_t tid2; // Identifiant du second thread
// Création du premier thread qui va directement aller
// exécuter sa fonction thread_routine.
pthread_create(&tid1, NULL, thread_routine, NULL);
printf("Main: Creation du premier thread [%ld]\n", tid1);
// Création du second thread qui va aussi exécuter thread_routine.
pthread_create(&tid2, NULL, thread_routine, NULL);
printf("Main: Creation du second thread [%ld]\n", tid2);
// Le main thread attend que le nouveau thread
// se termine avec pthread_join.
pthread_join(tid1, NULL);
printf("Main: Union du premier thread [%ld]\n", tid1);
pthread_join(tid2, NULL);
printf("Main: Union du second thread [%ld]\n", tid2);
return (0);
}
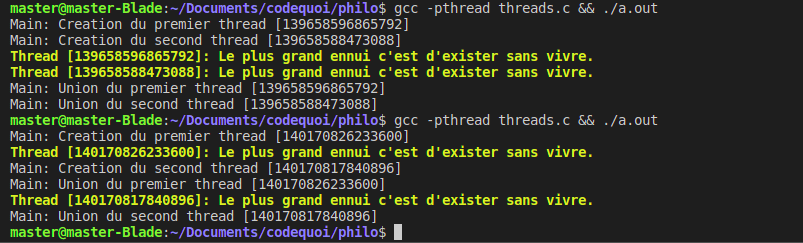
Quand on compile et qu’on lance ce test, on voit que les deux threads sont bien crées et affichent bien leurs identifiants. Si on lance le programme plusieurs fois d’affilée, on remarquera que les threads sont toujours crées dans l’ordre. Mais parfois, le main affiche son message avant le thread et vice-versa. Cela démontre bien que chaque thread s’exécute en effet de façon parallèle au thread principal, et non de façon séquentielle.
Gérer la mémoire partagée entre threads
Un des grands atouts des threads est qu’ils partagent tous la mémoire de leur processus. Chaque thread possède sa propre stack, oui, mais les autres threads peuvent très facilement y accéder à l’aide d’un simple pointeur. De plus, la heap et les descripteurs de fichiers ouverts sont complètement partagés entre les threads.
Cette mémoire partagée et cette facilité d’accès à la mémoire propre à un autre thread comporte aussi clairement ses dangers : cela peut être la cause de méchantes erreurs de synchronisation.
Erreurs de synchronisation
Reprenons notre exemple précédent et modifions-le pour voir comment la mémoire partagée des threads peut poser problème. On va créer deux threads et leur donner un pointeur vers une variable du main contenant un entier non-signé, count. Chaque thread va itérer un nombre déterminé de fois (défini dans la macro TIMES_TO_COUNT) et incrémenter le compteur count à chaque itération. Vu qu’il y a deux threads, on va bien sûr s’attendre à ce que le compte final soit exactement le double du TIMES_TO_COUNT.
#include <stdio.h>
#include <pthread.h>
// Chaque thread comptera TIMES_TO_COUNT fois
#define TIMES_TO_COUNT 21000
#define NC "\e[0m"
#define YELLOW "\e[33m"
#define BYELLOW "\e[1;33m"
#define RED "\e[31m"
#define GREEN "\e[32m"
void *thread_routine(void *data)
{
// Chaque thread commence ici
pthread_t tid;
unsigned int *count; // pointeur vers la variable dans le main
unsigned int i;
tid = pthread_self();
count = (unsigned int *)data;
// On imprime le compte avant que ce thread commence
// a itérer
printf("%sThread [%ld]: compte au depart = %u.%s\n",
YELLOW, tid, *count, NC);
i = 0;
while (i < TIMES_TO_COUNT)
{
// On itere TIMES_TO_COUNT fois
// On incremente le compte a chaque iteration
(*count)++;
i++;
}
// On imprime le compte final au moment ou ce thread
// a termine son propre compte
printf("%sThread [%ld]: Compte final = %u.%s\n",
BYELLOW, tid, *count, NC);
return (NULL); // Thread termine ici.
}
int main(void)
{
pthread_t tid1;
pthread_t tid2;
// Variable pour contenir le compte des deux threads :
unsigned int count;
count = 0;
// Vu que chaque thread va compter TIMES_TO_COUNT fois et qu'on va
// avoir 2 threads, on s'attend a ce que le compte final soit
// 2 * TIMES_TO_COUNT :
printf("Main: Le compte attendu est de %s%u%s\n", GREEN,
2 * TIMES_TO_COUNT, NC);
// Creation des threads :
pthread_create(&tid1, NULL, thread_routine, &count);
printf("Main: Creation du premier thread [%ld]\n", tid1);
pthread_create(&tid2, NULL, thread_routine, &count);
printf("Main: Creation du second thread [%ld]\n", tid2);
// Recuperation des threads :
pthread_join(tid1, NULL);
printf("Main: Union du premier thread [%ld]\n", tid1);
pthread_join(tid2, NULL);
printf("Main: Union du second thread [%ld]\n", tid2);
// Evaluation du compte final :
if (count != (2 * TIMES_TO_COUNT))
printf("%sMain: ERREUR ! Le compte est de %u%s\n", RED, count, NC);
else
printf("%sMain: OK. Le compte est de %u%s\n", GREEN, count, NC);
return (0);
}
Résultat :
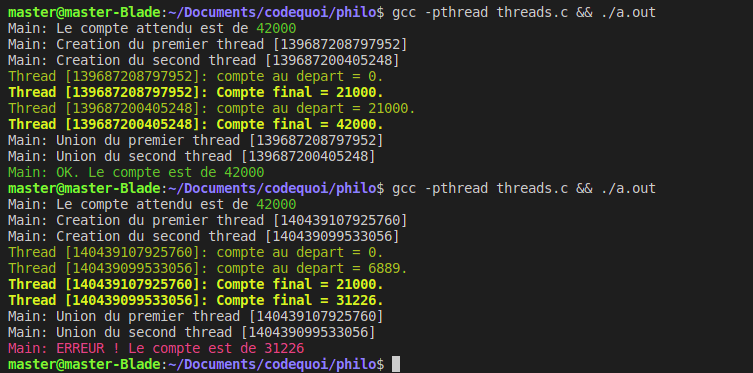
Tout à fait par hasard, la première fois qu’on lance le programme, le résultat sera peut être juste. Il ne faut pas se fier aux apparences ! La deuxième fois, le résultat est faux. Si on continue a exécuter le programme plusieurs fois de suite, on découvrira même qu’il est faux bien plus souvent que juste… Et le compte final varie beaucoup d’une exécution à l’autre : on ne peut même pas prédire le faux résultat. Alors que ce passe-t-il ici ?
Une situation de compétition : le “data race”
En examinant les résultats, on peut voir que le compte est juste si et seulement si le premier thread termine ses itérations avant que le deuxième commence. Dès que leurs exécutions se chevauchent, le résultat est faussé et toujours inférieur au résultat attendu.
Le problème, c’est donc que les deux threads accèdent souvent à la même zone mémoire en même temps. Disons que le compte est actuellement de 10. Le thread 1 lit la valeur 10. Plus précisément, il copie cette valeur 10 dans son registre pour pouvoir la manipuler. Ensuite, il ajoute 1 pour trouver le résultat de 11. Mais avant de pouvoir sauvegarder ce résultat à l’adresse mémoire de notre compte, le thread 2 y lit la valeur de 10. Le thread 2 incrémente donc aussi à 11. Les deux threads font alors leur sauvegarde, et voilà ! Au lieu d’avoir incrémenté le compteur une fois pour chaque thread, ils ne l’ont finalement incrémenté que d’une seule fois à eux deux… C’est pour ça qu’on perd des comptes et que notre résultat final considérablement est faussé.
Ceci s’appelle une situation de compétition ou un accès concurrent (" data race" en anglais). Ce genre de situation survient quand le programme dépend de la progression ou du timing d’autres événements incontrôlables. Et il est impossible de prédire si le système d’exploitation choisira le bon ordonnancement pour nos threads.
D’ailleurs, si on compile le programme avec les options -fsanitize=thread et -g avant de l’éxecuter, comme ceci :
gcc -fsanitize=thread -g threads.c && ./a.out
On nous avertira bien avec un “WARNING: ThreadSanitizer: data race”.
Alors, peut-on empêcher un thread de lire une valeur quand un autre thread la modifie ? Oui, à l’aide de mutex !
Qu’est-ce qu’un mutex ?
Un mutex (abrégé de " mut ual ex clusion" en anglais, c’est à dire “exclusion mutuelle”), c’est une primitive de synchronisation. C’est un essentiellement verrou qui permet de réguler l’accès aux données et empêcher que les ressources partagées soient utilisées en même temps.
On peut penser à un mutex comme au verrou de la porte des toilettes. Un thread vient le verrouiller pour indiquer que les toilettes sont occupées. Les autres threads devront alors attendre patiemment que la porte soit déverrouillée avant de pouvoir accéder aux toilettes à leur tour.
Déclarer un mutex
Avec le header <pthread.h>, on peut déclarer une variable de type mutex comme ceci :
pthread_mutex_t mutex;
Mais avant de pouvoir l’utiliser, on doit d’abord l’initialiser avec la fonction pthread_mutex_init qui a le prototype suivant :
int pthread_mutex_init(pthread_mutex_t *mutex,
const pthread_mutexattr_t *mutexattr);
On doit lui fournir deux paramètres :
- mutex : le pointeur vers une variable de type
pthread_mutex_t, le mutex qu’on souhaite initialiser. - mutexattr : un pointeur vers des attributs spécifiques pour le mutex. On ne se souciera pas de ce parametre ici, on mettra simplement
NULL.
La fonction pthread_mutex_init renvoie toujours 0.
Verrouiller et déverrouiller un mutex
Ensuite, pour verrouiller et déverrouiller notre mutex, il nous faudra deux autres fonctions qui ont les prototypes suivants :
int pthread_mutex_lock(pthread_mutex_t *mutex)); // Verrouillage
int pthread_mutex_unlock(pthread_mutex_t *mutex); // Déverrouillage
Si le mutex est déverrouillé, pthread_mutex_lock le verrouille et le thread appelant devient le propriétaire de ce mutex. La fonction prend alors fin immédiatement. Par contre, si le mutex est déjà verrouillé par un autre thread, pthread_mutex_lock suspend le thread appelant jusqu’à ce que le mutex soit déverrouillé.
Le fonction pthread_mutex_unlock, quand à elle, déverrouille un mutex. Ce mutex est supposé verrouillé par le thread appelant, et la fonction le réinitialise toujours à l’état déverrouillé. Attention, cette fonction ne vérifie pas si le mutex est en effet verrouillé et que le thread appelant est celui qui possède ce verrou : il est donc possible qu’un mutex soit déverrouillé par un thread autre que celui qui l’a verrouillé. Il faut donc faire particulièrement attention à la disposition des pthread_mutex_lock et pthread_mutex_unlock dans notre code pou éviter des erreurs du type “lock order violation”.
Ces deux fonctions renvoient 0 en cas de succès et un code erreur en cas d’erreur.
Détruire un mutex
Quand on n’a plus besoin d’un mutex, il nous faut le détruire avec la fonction pthread_mutex_destroy suivante :
int pthread_mutex_destroy(pthread_mutex_t *mutex);
Cette fonction détruit un mutex déverrouillé, libérant les ressources qu’il détient. Dans l’implémentation LinuxThreads des threads POSIX, aucune ressource ne peut être associé à un mutex. Dans ce cas, pthread_mutex_destroy ne fait rien si ce n’est vérifier que le mutex n’est pas verrouillé.
Exemple d’implémentation de mutex
On peut donc régler notre problème de compte faussé de l’exemple précédent en faisant usage d’un mutex. Pour cela, on va devoir créer une petite structure qui contiendra notre variable count ainsi que le mutex qui est censé la protéger. On pourra alors passer cette structure à la routine de nos threads.
#include <stdio.h>
#include <pthread.h>
// Chaque thread comptera TIMES_TO_COUNT fois
#define TIMES_TO_COUNT 21000
#define NC "\e[0m"
#define YELLOW "\e[33m"
#define BYELLOW "\e[1;33m"
#define RED "\e[31m"
#define GREEN "\e[32m"
// Structure pour contenir le compte ainsi que le mutex qui
// protegera l'accès à cette variable.
typedef struct s_counter
{
pthread_mutex_t count_mutex;
unsigned int count;
} t_counter;
void *thread_routine(void *data)
{
// Chaque thread commence ici
pthread_t tid;
t_counter *counter; // pointeur vers la structure dans le main
unsigned int i;
tid = pthread_self();
counter = (t_counter *)data;
// On imprime le compte avant que ce thread commence
// a itérer. Pour lire la valeur de count, on verrouille le
// mutex.
pthread_mutex_lock(&counter->count_mutex);
printf("%sThread [%ld]: compte au depart = %u.%s\n",
YELLOW, tid, counter->count, NC);
pthread_mutex_unlock(&counter->count_mutex);
i = 0;
while (i < TIMES_TO_COUNT)
{
// On itere TIMES_TO_COUNT fois
// On verouille le mutex le temps
// d'incrementer le compte
pthread_mutex_lock(&counter->count_mutex);
counter->count++;
pthread_mutex_unlock(&counter->count_mutex);
i++;
}
// On imprime le compte final au moment ou ce thread
// a termine son propre compte en verouillant le mutex
pthread_mutex_lock(&counter->count_mutex);
printf("%sThread [%ld]: Compte final = %u.%s\n",
BYELLOW, tid, counter->count, NC);
pthread_mutex_unlock(&counter->count_mutex);
return (NULL); // Thread termine ici.
}
int main(void)
{
pthread_t tid1;
pthread_t tid2;
// Structure pour contenir le compte des deux threads :
t_counter counter;
// Il n'y a ici qu'un seul thread, on peut donc initialiser
// le compte sans mutex.
counter.count = 0;
// Initialisation du mutex :
pthread_mutex_init(&counter.count_mutex, NULL);
// Vu que chaque thread va compter TIMES_TO_COUNT fois et qu'on va
// avoir 2 threads, on s'attend a ce que le compte final soit
// 2 * TIMES_TO_COUNT :
printf("Main: Le compte attendu est de %s%u%s\n", GREEN,
2 * TIMES_TO_COUNT, NC);
// Creation des threads :
pthread_create(&tid1, NULL, thread_routine, &counter);
printf("Main: Creation du premier thread [%ld]\n", tid1);
pthread_create(&tid2, NULL, thread_routine, &counter);
printf("Main: Creation du second thread [%ld]\n", tid2);
// Recuperation des threads :
pthread_join(tid1, NULL);
printf("Main: Union du premier thread [%ld]\n", tid1);
pthread_join(tid2, NULL);
printf("Main: Union du second thread [%ld]\n", tid2);
// Evaluation du compte final :
// (Ici on peut lire le compte sans s'occuper du mutex
// car tous les threads sont unis et on a la garantie
// qu'un seul un thread va y acceder.)
if (counter.count != (2 * TIMES_TO_COUNT))
printf("%sMain: ERREUR ! Le compte est de %u%s\n",
RED, counter.count, NC);
else
printf("%sMain: OK. Le compte est de %u%s\n",
GREEN, counter.count, NC);
// On detruit le mutex à la fin du programme :
pthread_mutex_destroy(&counter.count_mutex);
return (0);
}
Voyons voir si notre résultat est toujours faux :
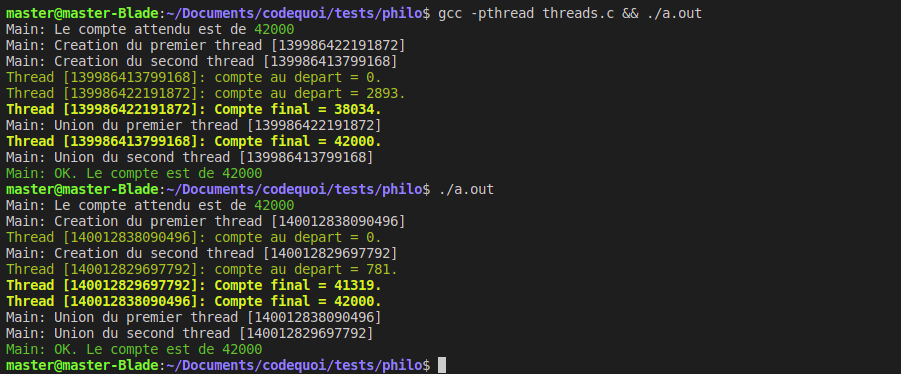
Et voilà ! Notre résultat est maintenant juste à chaque fois qu’on lance le programme, même si le deuxième thread commence à compter avant que le premier n’ait terminé.
Attention aux “deadlock”
Cependant, ces mutex provoquent souvent des interblocages (ou “deadlock” en anglais). C’est une situation dans laquelle chaque thread attend une ressource détenue par un autre thread. Par exemple, thread T1 a acquis le mutex M1 et attend le mutex M2. Entre temps, le thread T2 a acquis le mutex M2 et attend le mutex M1. Dans ce cas, le programme reste en suspens et doit être tué.
Un interblocage peut aussi arriver lorsqu’un thread attend un mutex qu’il possède déjà !
Tentons de démontrer un interblocage. Dans cet exemple, on aura deux threads qui, pour pouvoir incrémenter un compteur, doivent verrouiller deux mutex, lock_1 et lock_2. Les routines de ces deux threads sont un peu différentes : le premier thread verrouillera lock_1 en premier, tandis que le thread 2 commence par verrouiller lock_2…
#include <stdio.h>
#include <pthread.h>
#define NC "\e[0m"
#define YELLOW "\e[33m"
#define BYELLOW "\e[1;33m"
#define RED "\e[31m"
#define GREEN "\e[32m"
typedef struct s_locks
{
pthread_mutex_t lock_1;
pthread_mutex_t lock_2;
unsigned int count;
} t_locks;
// Le premier thread invoque cette routine :
void *thread_1_routine(void *data)
{
pthread_t tid;
t_locks *locks;
tid = pthread_self();
locks = (t_locks *)data;
printf("%sThread [%ld]: veut verrouiller lock 1%s\n", YELLOW, tid, NC);
pthread_mutex_lock(&locks->lock_1);
printf("%sThread [%ld]: possede lock 1%s\n", BYELLOW, tid, NC);
printf("%sThread [%ld]: veut verrouiller lock 2%s\n", YELLOW, tid, NC);
pthread_mutex_lock(&locks->lock_2);
printf("%sThread [%ld]: possede lock 2%s\n", BYELLOW, tid, NC);
locks->count += 1;
printf("%sThread [%ld]: deverouille lock 2%s\n", BYELLOW, tid, NC);
pthread_mutex_unlock(&locks->lock_2);
printf("%sThread [%ld]: deverouille lock 1%s\n", BYELLOW, tid, NC);
pthread_mutex_unlock(&locks->lock_1);
printf("%sThread [%ld]: termine%s\n", YELLOW, tid, NC);
return (NULL); // Le thread termine ici.
}
// Le deuxieme thread invoque cette routine :
void *thread_2_routine(void *data)
{
pthread_t tid;
t_locks *locks;
tid = pthread_self();
locks = (t_locks *)data;
printf("%sThread [%ld]: veut verrouiller lock 2%s\n", YELLOW, tid, NC);
pthread_mutex_lock(&locks->lock_2);
printf("%sThread [%ld]: possede lock 2%s\n", BYELLOW, tid, NC);
printf("%sThread [%ld]: veut verrouiller lock 1%s\n", YELLOW, tid, NC);
pthread_mutex_lock(&locks->lock_1);
printf("%sThread [%ld]: possede lock 1%s\n", BYELLOW, tid, NC);
locks->count += 1;
printf("%sThread [%ld]: deverouille lock 1%s\n", BYELLOW, tid, NC);
pthread_mutex_unlock(&locks->lock_1);
printf("%sThread [%ld]: deverouille lock 2%s\n", BYELLOW, tid, NC);
pthread_mutex_unlock(&locks->lock_2);
printf("%sThread [%ld]: termine%s\n", YELLOW, tid, NC);
return (NULL); // Le thread termine ici.
}
int main(void)
{
pthread_t tid1; // Identifiant du premier thread
pthread_t tid2; // Identifiant du second thread
t_locks locks; // Structure contenant 2 mutex
locks.count = 0;
// Initialisation des deux mutex :
pthread_mutex_init(&locks.lock_1, NULL);
pthread_mutex_init(&locks.lock_2, NULL);
// Création des threads :
pthread_create(&tid1, NULL, thread_1_routine, &locks);
printf("Main: Creation du premier thread [%ld]\n", tid1);
pthread_create(&tid2, NULL, thread_2_routine, &locks);
printf("Main: Creation du second thread [%ld]\n", tid2);
// Union des threads :
pthread_join(tid1, NULL);
printf("Main: Union du premier thread [%ld]\n", tid1);
pthread_join(tid2, NULL);
printf("Main: Union du second thread [%ld]\n", tid2);
// Évaluation du résultat :
if (locks.count == 2)
printf("%sMain: OK: Le compte est %d\n", GREEN, locks.count);
else
printf("%sMain: ERREUR: Le compte est%u\n", RED, locks.count);
// Destruction des mutex :
pthread_mutex_destroy(&locks.lock_1);
pthread_mutex_destroy(&locks.lock_2);
return (0);
}
Comme on peut le voir dans le résultat ci-dessous, la plupart du temps, il n’y a pas de problème avec cette configuration parce que le premier thread a un tout petit peu d’avance sur le deuxième. Mais parfois, les deux threads verrouillent leur premiers mutex exactement en même temps, et dans ce cas, le programme reste bloqué.
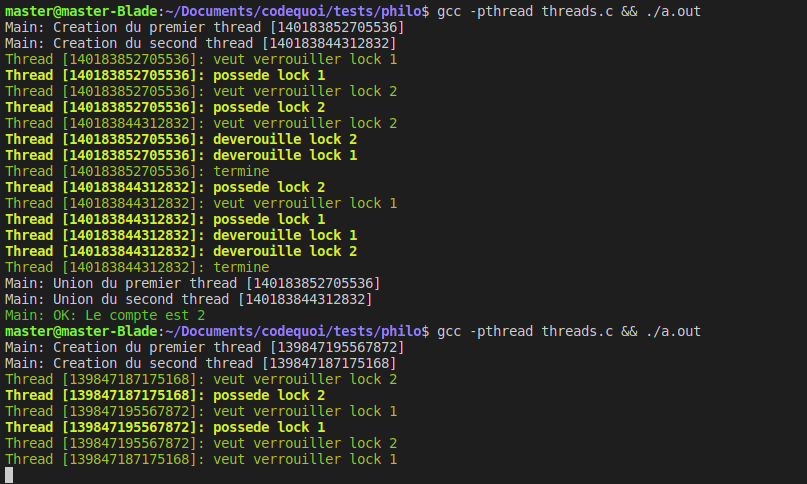
Si on étudie bien ce deuxième résultat, on peut voir que le deuxième thread a verrouillé lock_2 et le premier a verrouillé lock_1. Le premier thread veut maintenant verrouiller lock_2 et le deuxième veut verrouiller lock_1 mais aucun des deux n’ont l’occasion de le faire. Ils sont interbloqués.
Gérer les interblocages
Il y a plusieurs façons de gérer les interblocages comme ceux-ci. On peut entre autres :
- les ignorer, mais seulement si on peut prouver qu’ils ne surviendront jamais. Par exemple, quand les intervalles de temps entre les demandes d’accès aux ressources partagées sont très longues.
- les corriger quand ils surviennent en tuant un thread ou en redistribuant les ressources, par exemple.
- les prévenir et les corriger avant qu’ils ne surviennent.
- les éviter en imposant un ordre strict d’acquisition des ressources. C’est la solution à notre exemple précédent : les threads devraient demander tous deux le
lock_1en premier. - les éviter en forçant un thread a relâcher une ressource avant d’en demander de nouvelles ou de renouveler sa demande.
Il n’y a pas de “meilleure” solution pour gérer tous les cas d’interblocage. La méthode de gestion des interblocages doit se faire au cas par cas, selon la situation.
Astuces pour tester les threads d’un programme
L’important quand on teste un programme qui fait appel à de multiples threads, c’est de tenter chaque test plusieurs fois de suite. En effet, il arrive souvent que des erreurs de synchronisation ne soient pas détectables lors du premier, du deuxième ou même du troisième résultat. Cela dépend du choix d’ordonnancement du système d’exploitation lors de cette exécution des threads. En tentant le même test de façon répétée, il arrive régulièrement d’avoir des résultats très différents les uns des autres.
Il y a quelques outils qui peuvent nous aider à détecter les erreurs liés aux threads comme les situations de compétition ( data race), les possibilités d’interblocage ( deadlock) et les erreurs d’acquisition de mutex ( lock order violation) :
- Le drapeau
-fsanitize=thread -gqu’on ajoute au moment de la compilation. L’option-gpermet d’afficher les numéros de ligne qui ont produit l’erreur. - L’outil de détection d’erreurs de thread Helgrind avec lequel on peut exécuter notre programme, comme ceci :
valgrind --tool=helgrind ./programme. - L’outil de détection d’erreurs de threads DRD, qu’on lance aussi au moment de l’exécution comme ceci :
valgrind --tool=drd ./programme.
Attention, valgrind et -fsanitize=thread ne s’entendent pas du tout et ne doivent pas s’utiliser ensemble !
Comme toujours, il ne faut pas non plus oublier de vérifier les fuites de mémoire avec -fsanitize=address et valgrind tout court !
Une autre astuce à partager, une petite question à poser, ou une découverte intéressante à propos des threads ou des mutex ? Je serai ravie de lire et de répondre à tout ça dans les commentaires. Bon code !
Sources et lectures supplémentaires
- Bryant, R., O’Hallaron, D., 2016, Computer Systems: a Programmer’s Perspective, Chapter 12: Concurrent Programming, p. 1007 - 1076
- Arpaci-Dusseau R., Arpaci-Dusseau, A., 2018, Operating Systems: Three Easy Pieces, Part II: Concurrency [ OSTEP]
- Wikipédia, Programmation concurrente [ Wikipédia]
- Wikipédia, Exclusion mutuelle [ Wikipédia]
- Manuel du programmeur Linux :
- Valgrind User Manual, Helgrind: a thread error detector [ valgrind.org]
- Valgrind User Manual, DRD: a thread error detector [ valgrind.org]